

Todos hemos oído decir que Google se sirve de machine learning o aprendizaje automático para ordenar sus resultados. Pero, ¿en qué casos y algoritmos concretos se usan estos métodos automáticos, y cómo lo hacen?
Algunas nociones básicas de machine learning, y por qué debe usarlo Google
Google hizo más de 5150 cambios a su buscador en 2021. No todas estas modificaciones afectan a los rankings (pueden afectar también a la presentación de los resultados) y algunos son sólo tests temporales. Pero con tal volumen de cambios, es lógico que muchos de ellos dependan de sistemas automáticos, en lugar de ser cambios hechos a mano, o fruto de un algoritmo tradicional.

Facebook, TikTok… Todas las compañías Big Tech, que dan servicio a millones de usuarios diarios, necesitan sistemas de aprendizaje automático para poder procesar cantidades ingentes de datos y dar su servicio. Google es quizá el caso más claro.
Pero antes, veamos qué es aprendizaje automático. El aprendizaje automático (en inglés Machine Learning o ML) es una rama de la Inteligencia Artificial enfocada en imitar el aprendizaje humano. Lo interesante es que puede hacerlo a una escala gigantesca.
El aprendizaje automático usa métodos estadísticos para clasificar, predecir o extraer conclusiones de fuentes enormes de datos. Sin un input previo de datos no hay ML, igual que una persona tampoco aprende de la nada.
Aprendizaje automático vs redes neuronales vs deep learning
El aprendizaje automático no es sólo redes neuronales y deep learning. En los medios se suelen usar estos términos como sinónimos de ML, pero son sólo una parte (las redes neuronales o neural networks son un subcampo del aprendizaje automático, y a su vez deep learning o aprendizaje profundo es un subcampo de las redes neuronales). Hay también otros métodos de aprendizaje automático, como Naive Bayes, regresiones lineales, clustering, random forests, Support Vector Machines (SVMs)…
Si quieres leer una introducción básica y muy visual al aprendizaje automático, te recomiendo esta guía.
¿Cómo usa Google el aprendizaje automático a efectos de ranking?
Aunque muy probablemente Google ya usaba antes métodos de ML en su buscador, la confirmación oficial llegó a finales de 2015, cuando en Mountain View anunciaron oficialmente RankBrain, un sistema de aprendizaje automático que es usado en labores de ranking.
BERT y su aplicación a la búsqueda
Desde entonces, se han reconocido de manera oficial varios sistemas basados en ML que afectan a ranking y a otras áreas (como por ejemplo su sistema de reescritura de Titles). En 2019, se anunció que ya se se usaba BERT para comprender el significado de una pequeña parte de las búsquedas en inglés y hasta 70 idiomas. BERT es una tecnología open-source desarrollada por Google y basada en redes neuronales, que permite entrenar modelos de procesamiento de lenguaje natural (NLP) con una sofisticación nunca conseguida antes.
MUM y su aplicación a la búsqueda
Pero la inteligencia artificial avanza rápido y en 2021 Google presentó MUM, que describía como 1000 veces más potente que BERT. Google no ha aplicado MUM aún a tareas relacionadas con el rankeo de resultados, aunque sí la está usando en algunas tareas puntuales dentro del buscador, como por ejemplo identificar los nombres de las vacunas del Covid en cada idioma, o para evitar que los fragmentos destacados devuelvan respuestas correctas, pero a preguntas sin sentido, como por ejemplo «¿cuándo asesinó Snoopy a Abraham Lincoln?»
Updates que afectan a ranking y usan ML
Respecto a labores de ranking, entre los últimos updates confirmados oficialmente en los dos últimos años, la mayoría usan total o parcialmente sistemas de ML (core updates, spam y link spam updates, reseñas de productos y Helpful Content). La excepción más clara es el update de Experiencia de Página, donde el criterio para recibir un empujón en los ranking es simplemente si la página aprueba las tres Core Web Vitals y otros requisitos de experiencia de usuario. No hay ML implicado.
Un caso particular: el update de reseñas de producto
Aunque puede haber también otros métodos, tenemos una explicación por parte de un googler sobre el sistema usado por el update de reseñas de producto (explicación que muy probablemente sea extensible al Helpful Content Update).
La explicación se encuentra en esta entrevista por parte de Marie Haynes a Alan Kent, Developer Advocate y encargado dentro de Google de las labores de comunicación en torno al Product Reviews Update (a partir del minuto 19):
De manera resumida, el clasificador usado por Google funciona así:
- Los ingenieros definen características de los datos a analizar en los que el sistema debe fijarse: estos pueden ser palabras, frases o imágenes de las páginas a clasificar, pero también el luegar desde el que busca el usaurio.
- Proporcionan ejemplos al sistema de lo que consideran buenas reseñas/contenidos y ejemplos de lo que consideran malas reseñas/contenidos.
- El sistema busca patrones comunes para los buenos y malos ejemplos, y después usa estos patrones para clasificar nuevos casos (páginas que no ha visto nunca) en buenos o malos. Los ingenieros no conocen ni definen estos patrones, es la IA quien encuentra el criterio óptimo de clasificación.
Ejemplo: puede haber una mayor correlación con buenas reseñas cuando estas incluyen imágenes originales que demuestran que su autor ha probado el producto (este ejemplo seguramente sea real, ya que Google ha anunciado que en el futuro será factor positivo de ranking para reseñas).
¿Es este método un «arma secreta» de Google, que sólo ellos conocen y aplican? No. Si buscamos la definición «académica» de un clasificador en Machine Learning, encontraremos una explicación muy parecida.
Llevando lo visto anteriormente a los términos usados comúnmente en ML, los ejemplos de buenas/malas webs serían el training data-set, o los datos de entrenamiento, etiquetados por los ingenieros de Google para que el sistema pueda aprender; las características en las que el sistema debe fijarse serían las dimensiones o variables del modelo, los patrones encontrados por el sistema serían los pesos que este asigna a cada variable para dar con el output ideal. Se trata de una tarea de aprendizaje supervisado.
Por qué Google sigue combinando algoritmos tradicionales y ML
¿Quiere todo esto decir que Google ya no necesita algoritmos «tradicionales», como por ejemplo PageRank, y que lo fía todo al ML?
No. Pasar toda la responsabilidad al «piloto automático» tendría enormes desventajas, entre ellas que sería imposible depurar un error puntual.
Por ejemplo, hace unos años en respuesta a la pregunta «¿sucedió el Holocausto?», Google daba como primera respuesta una página que lo negaba (fuente: Trillions of Questions, No Easy Answer, minuto 31)
Los ingenieros vieron que en ese caso, y otros parecidos, el sistema primaba la relevancia (respuesta explícita a la pregunta del usuario) por encima de la calidad o autoridad de la página. La solución: elevar manualmente, en ciertas temáticas, el peso de las señales de autoridad.
Esto con un sistema controlado totalmente por ML sería imposible, ya que no sabrían por qué la máquina ha llegado al output erróneo. Para solucionarlo necesitarían reprogramar todo de cero. Con métodos tradicionales, sí es posible aislar el error y arreglar sólo la parte responsable.
Esto hace que los lanzamientos de algoritmos de ML deban testearse con más rigor aún. Incluso superado el testeo previo, Google no lanza estos updates de golpe, sino en varias iteraciones, para observar su efecto sobre los resultados reales, y poder corregir lo antes posible.
¿Decepcionado con los efectos del primer Helpful Content Update? Al ser la primera iteración de este algoritmo, en Google han preferido ser conservadores, en lugar de pasarse de frenada y perjudicar a sitios que incumplan sólo parcialmente sus requisitos de contenido útil. En mi post puedes ver algunos ejemplos de webs afectadas en el primer lanzamiento del HCU, y juzgar si el clasificador está funcionando correctamente o no:
Por cierto, aprovecho para decir que tanto el update de reseñas de producto, como el HCU, por el momento sólo se dirigen a webs en inglés.
Esto no tiene nada de extraño. ¿Recuerdas que para que un algoritmo de ML sea efectivo necesita una gran cantidad de datos? Parece lógico entonces que en Google hayan optado por afinar primero estos dos updates con datos de webs en inglés, idioma en el que hay más contenido disponible en internet, y luego una vez afinados, llevar los updates a otros idiomas.
Un cabo suelto: ¿Qué es DeepRank?
Si ves Trillions of Questions, No Easy Answers, el documental que he insertado al hablar de los resultados que negaban el Holocausto (y lo recomiendo, porque es buenísimo) verás que dedican cerca de media hora a hablar de un proyecto llamado DeepRank.
DeepRank es un sistema basado en deep learning y destinado a la comprensión de búsquedas «difíciles» para Google. En el documental vemos cómo su lanzamiento es aprobado por los jefazos de Google Search. ¿Cómo es que no he hablado hasta ahora de este algoritmo?
En realidad sí lo he mencionado, sólo que no con ese nombre, que es el que usan internamente para referirse a la aplicación de BERT al buscador. Su lanzamiento se anunció oficialmente en octubre de 2019, como explica este post de Google.
¿Qué hace diferente a Deep Rank de algoritmos anteriores? Para empezar, no ignora las “stop words”, las palabras más frecuentes en cualquier idioma: artículos (el, la…), pronombres (yo, tu…), preposiciones (a, ante, cabe…), etc. Los métodos tradicionales de Information Retrieval ignoraban estas palabras, centrándose en nombres, adjetivos y verbos.
Así, “vuelo de Madrid a Las Palmas” para un buscador tradicional quedaría convertida en “vuelo madrid palmas”. Pero “vuelo a Madrid por Las Palmas” y “vuelo a Madrid y Las Palmas”, que no quieren decir lo mismo, también quedarían limitadas a “vuelo madrid palmas”.
La efectividad de DeepRank para búsquedas en las que ciertas preposiciones o palabras muy frecuentes pueden cambiar totalmente el sentido de la frase se ve en este ejemplo concreto mostrado por la película: “can you get medicine for someone pharmacy”. Traducida a español, la búsqueda sería “puedes comprar medicinas para otra persona en la farmacia”.
En la imagen siguiente, vemos a la izquierda el resultado elegido por DeepRank como más relevante, con el título “Can a patient have a friend or family member pick up a prescription…” La coincidencia en cuanto a intención de búsqueda es total.
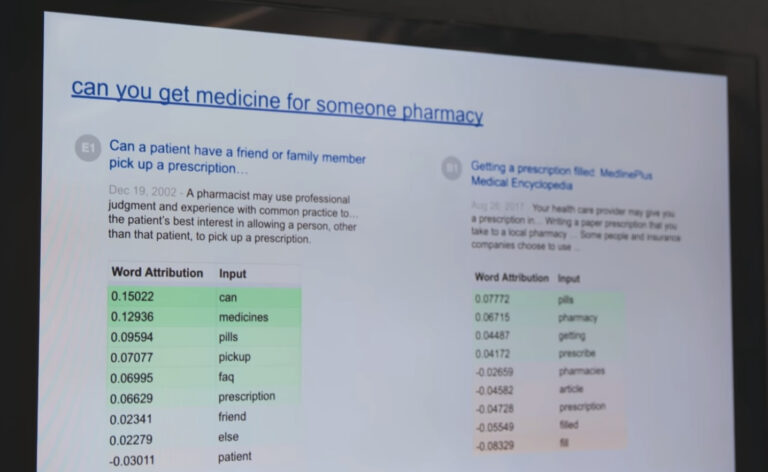
Por el contrario, a la derecha vemos el resultado ofrecido como Top 1 por Google antes del lanzamiento de DeepRank, con el título de “Getting a prescription filled”. Traducido a español, sería más o menos “Cómo obtener un medicamento que se te ha recetado”, por tanto es un artículo de carácter mucho más general sobre el funcionamiento de las recetas y farmacias en Estados Unidos, pero sin mención específica al problema de envíar a alguien a recoger tu medicina. De hecho, no incluía menciones a términos que serían fundamentales para el contexto real de la búsqueda, como “friend”, “else” o “patient”.
Mi ponencia en el SEOnderground: Updates de Google, aprendizaje automático y el dilema de la comunicación
Cerrado este cabo suelto, te dejo para acabar la presentación completa de mi ponencia en el evento SEOnderground 2022, donde también traté de los updates de Google en general, y de la comunicación que hacen de estos updates:
