

Este post está basado en un excelente artículo de Jason Barnard para Search Engine Journal. En él, Barnard explica con bastante detalle una respuesta que le dio Gary Illyes sobre el sistema por el que Google elige si va a mostrar un resultado orgánico normal (un clásico link azul) o un resultado enriquecido, como por ejemplo un featured snippet.
Para dar esta explicación, Illyes compartió con Barnard (y él con nosotros), un resumen de lo que los nuevos ingenieros aprenden al llegar a Google sobre el funcionamiento del algoritmo de ranking. Era una información demasiado jugosa como para no analizarla todo lo posible y compartirla con vosotros en USEO.
Todo lo que hay hasta el punto 4 es una adaptación, con mis palabras, del post de Jason. A partir del punto 4, sin embargo, hay cosas de mi propia cosecha, basadas en lo que he podido encontrar en las patentes concedidas a Google sobre conceptos que tienen que ver con el sistema descrito por Illyes.
Qué aprenden los nuevos ingenieros de Google sobre el proceso de rankeo
Básicamente, lo que llamamos ranking viene determinado por la multiplicación de un grupo de puntuaciones, cada una de las cuales corresponde a un grupo de factores de posicionamiento en el algoritmo de Google.
Siete de estos grupos son Topicality (Temática), Quality (Calidad), PageSpeed (Velocidad de carga), Entities (Entidades), RankBrain, Structured Data (Datos estructurados) y Freshness (Actualidad o frescura). La traducción es mía, pero los términos en inglés son los que usan internamente en Google, según Gary Illyes.
Actualizado septiembre 2019: en mi conversación con Gary Illyes en el pasado SEonthebeach, este me dijo que Structured Data no era un grupo de factores de ranking, y que sólo afectaba a la capacidad o no de mostrar resultados enriquecidos en la SERP. Por el contrario, me dijo que otros grupos de factores que sí podía revelar eran SafeSearch y Country. Y también me dijo que había dos grupos de factores que si los revelase, sería inmediatamente despedido de Google. 😉
Ahora viene lo malo, lo que no sabemos.
1) Estos 7 grupos no son los únicos que se usan para calcular el ranking. Puede haber más grupos de factores en la ecuación.
2) No sólo eso, sino que no sabemos los factores o señales individuales que conforman cada grupo de factores (aunque Gary ha dejado caer algunos y podemos imaginarnos otros). Pero sobre todo, no sabemos el “peso” de cada factor individual dentro de su grupo.
Sabemos que dentro de Quality está PageRank, pero hay otras señales. Dentro de Structured Data está el uso de schema.org, pero también el uso de tablas, HTML5 semántico y muchos otros.
En resumen: no sabemos las piezas que faltan, ni su importancia relativa.
Tenemos una visión general, bastante esclarecedora, pero nos faltan los detalles, la mecánica del rankeo. Y eso Google nunca lo va a dar.
Pero sigo con lo que sí sabemos: las puntuaciones de cada grupo de factores se multiplican entre sí, y de ahí sale una puntuación total o “puja” (bid, término que también es de Google y que también se usa en Google Ads).
A mayor puja, más alta la posición en el ranking, al menos hasta que llega la fase de re-ranking, que es como reordenar los resultados de una SERP de acuerdo a criterios o filtros puntuales, que no salen de los grupos de factores básicos (esto lo explico en el punto 3).

Contexto: ¿de dónde sale esta información?
Como he dicho, lo que he explicado hasta aquí no es teoría mía.
Viene de una explicación de Gary Illyes, Webmaster Trends Analyst y uno de los empleados de Google encargados del contacto con la comunidad de webmasters, en respuesta a una pregunta de Jason Barnard.
Jason preguntó específicamente si existía un algoritmo para rankear los resultados orgánicos normales (los clásicos 10 enlaces azules de toda la vida) y otro algoritmo para decidir los fragmentos destacados o featured snippets que suelen aparecer en lo más alto de la SERP.
Gary respondió contándole lo que un nuevo ingeniero aprende en cuanto llega al departamento de búsqueda de Google.
Por si tenéis dudas de si esto es lo que realmente Gary le contó a Jason, había unos 20 testigos. Un grupo de periodistas y SEOs, ya que la respuesta se dio en medio de un encuentro con la comunidad en el Search Marketing Summit de Sydney.
Jason Barnard pidió permiso a Gary para publicar su explicación y Gary se lo dio, comentando que todo esto son conceptos generales y que ya se conocían. Cierto que no es del todo específico, pero en mi opinión aclara muchas cosas y rechaza otras, que la comunidad SEO/webmasters tiende a dar por ciertas.
Relaciones entre los grupos de factores de ranking y cómo se calcula una “puja”
Vamos a lo que nos importa a los SEOs. Lo primero, hay que saber que hay un tope por encima del cual el valor de una puja no puede pasar, por mucho que aumenten los valores de uno o varios grupos de factores.
Esto quiere decir que Google ha puesto un techo a la fuerza que un grupo de factores puede aportar al valor total, más allá del cual no se puede pasar. Si ya eres increíblemente fuerte en enlaces, por ejemplo, puede que llegue un momento en el que seguir añadiendo enlaces, por buenos que sean, no tenga ninguna incidencia. Aunque como no sabemos los valores reales de nada, esto no tiene aplicación práctica, ni podemos decir cuánto son muchos enlaces o mucha autoridad.
Al revés, en cambio, sí que hay una aplicación de mucho más valor para el SEO. Si un grupo concreto tiene una puntuación muy baja esto hace caer el valor total de la puja de manera drástica.
Es decir, tener una puntuación extremadamente baja en un grupo de factores te condena de cara a posicionar en Google, aunque el resto de grupos tengan puntuaciones buenas o muy buenas. Diríamos que conviene más tener puntuaciones medianas en todos los grupos, que una sola baja y el resto muy altas.
Desde el punto de vista del trabajo de un SEO, merece más la pena optimizar para pasar de una puntuación mala a normal en un grupo concreto, que tratar de mejorar “un poquito” las puntuaciones de todos los grupos.
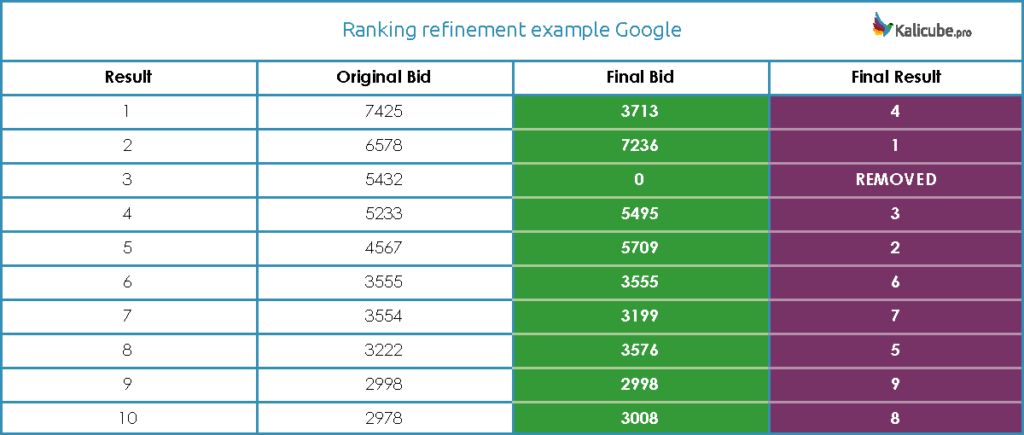
Vamos a verlo con un ejemplo, basado en los ejemplos que muestra Jason Barnard en su post (importante: los números son ficticios y no pretenden representar valores reales asignados por Google).
| Temática | Calidad | Vel. de carga | RankBrain | Entidades | Datos estr. | Actualidad | Factor X | Puja | |
| URL 1 | 5 | 6 | 4 | 7 | 5 | 8 | 5 | 6 | 1008000 |
| URL 2 | 5 | 6 | 4 | 7 | 0.1 | 8 | 5 | 6 | 20160 |
| URL 3 | 3 | 4 | 3 | 3 | 4 | 4 | 3 | 4 | 20736 |
URL 1 y URL 2 tienen valores bastante buenos e idénticos en todos los grupos, salvo por el grupo Entidades, donde la URL 1 tiene un 5 y la URL 2 un 0.1 (desastre total).
La URL 3, en cambio, es bastante mediocre en todos los valores, siempre por debajo de 4. Pero no tiene un 0.1 en ningún campo.
Al final, la URL 1 siempre estaría en lo alto, pero la URL 3 se cuela por delante de la 2, y eso que esta última le gana en todos los grupos menos uno.
Re ranking o modificadores del ranking
Por si fuera esto poco, nos falta saber el último paso antes de rankear resultados: la fase de re ranking, o ajuste de los rankings, en base a modificadores que se calculan aparte del grupo de factores original.
Esta fase sólo afecta a los resultados colocados en el Top por los grupos de factores convencionales. Digamos los 10 primeros, o lo que tradicionalmente es la primera página de Google para una búsqueda determinada. El resto de la SERP no sería reordenada en la fase de re ranking.
Sabemos también que los factores que actúan en la fase de re ranking son más específicos que los grupos de la fase de ranking normal. Es decir, sirven para ajustar los rankings en casos puntuales, que se le escapan al algoritmo general.
Según Jason, podría tratarse ante todo de filtros destinados a ajustar a la baja algunos resultados anormalmente beneficiados por el cálculo convencional. Por ejemplo, se trataría de bloquear o devaluar resultados de poca relevancia, baja calidad o directamente black hat.
Yo, en cambio, creo que hay evidencia de que en ciertos casos Google no lo usa con intención de penalizar, sino simplemente de ajustar con más precisión la relevancia de los resultados.
Como ejemplo, hace sólo unos meses Google publicó en el blog de ai.google un paper titulado Deep Relevance Ranking using Enhanced Document-Query Interactions, en el cual dicen a las claras que el nuevo método propuesto actuaría re-rankeando documentos ordenados previamente por métodos tradicionales.
Inciso: aunque no me voy a meter a desgranar este paper, porque se sale del tema del post y además es bastante denso, recomiendo este post de Roger Monti sobre el tema, y dejo en plan spoiler que el método descrito está muy relacionado con el anuncio de Neural Matchings y super synonims que hizo Danny Sullivan (Google Search Liaison) a finales de septiembre de 2018.
En conclusión: Google tiene métodos para reordenar las serps, o una serp en concreto, si no le “gusta” del todo el orden arrojado por la interacción entre los grupos de factores convencionales.
Y esta fase puede bajar o subir la posición de un resultado orgánico del Top 10, o incluso hacer desaparecer totalmente a ese resultado del ranking (con lo cual todos los resultados situados detrás avanzarían una posición).
Todos estos cambios dependen de la puntuación puntuación, positiva, negativa o incluso nula, que reciba un resultado en la fase de re ranking.
¿Qué nos dicen las patentes de Google de cada grupo de factores?
Hasta ahora he seguido casi al pie de la letra el post de Jason, pero ahora voy a aportar algo propio.
En mi opinión, que Google llame así, y no de otra forma, a los grupos de factores es muy importante, porque eso nos permite ir a las patentes de Google y encontrar todas las patentes que tienen que ver con el proceso de ranking y que usan estos términos.
Por supuesto, que algo haya sido patentado por Google no quiere decir que necesariamente lo use en su algoritmo, o que lo haya usado en algún momento. Y que en la patente use los mismos nombres que en los grupos de factores revelados por Gary Illyes tampoco garantiza que se usen, o que se usen tal y como se describe.
Pero en mi opinión empieza a ser demasiada coincidencia, sobre todo cuando la patente describe comportamientos que tienen mucho que ver con fenómenos que los SEOs hemos observado y que no se explican del todo de acuerdo al concepto tradicional de factores SEO Off Page y On Page.
Me voy a limitar a explorar Topicality y Quality, lo que no quiere decir que los otros grupos no sean importantes. Lo hago porque son conceptos más generales o abstractos, y porque las patentes que he encontrado tienen más “chicha”. Y también porque si analizo todosl os grupos, entonces este post no acabaría nunca. 😉
Primero describo de manera resumida la patente y luego aporto mi opinión, tratando de relacionarla con las explicaciones de Gary Illyes.
No lo toméis como dogma. Simplemente estoy explorando y tratando de aportar cosas que nos ayuden a todos a reevaluar ciertas cosas dentro del SEO. Me interesa más crear debate y contribuir a que nos replanteemos conceptos, que dar una clase magistral sobre cómo creo que funcionan los rankings en Google. Eso sólo lo saben Gary y cía.
Topicality (Temática)
He encontrado dos patentes relacionadas con el posicionamiento y que usan de manera prominente este término o uno derivado.
Systems and methods for correlating document topicality and popularity
Número: US8595225B1
Fecha de presentación: 30 de septiembre de 2004
Concedida: 26 de noviembre de 2013
Autores: Amit Singhal y Urs Hoelzle
Resumen: Amit Singhal ha sido jefe de Search en Google por 15 años y fue el encargado de reescribir el algoritmo de Google en 2001, como cuento en mi post sobre la historia de Google.
Esta patente propone usar datos de visitas de usuarios para determinar la popularidad de un documento, al tiempo que mapeamos los topics o temas que toca ese documento. Con esto, podemos rankear los documentos por popularidad dentro de la temática o temáticas que toca.
Mi opinión: Esto podría querer decir que la puntuación del grupo Topicality, entre otros factores, dependería del puesto que ocupe en popularidad un documento dentro de su topic concreto.
¿Cómo puede saber Google datos de popularidad de los documentos? Podría basarse únicamente en los logs del buscador (cuántas impresiones orgánicas recibe un documento, por ejemplo, dato que tenemos todos en nuestro Search Console), pero hay otros métodos, como explico en este post que analiza una patente sobre el tráfico web como señal de ranking.
Search query results based upon topic
Número: US8620951B1
Fecha de presentación: 28 de enero de 2012
Concedida: 31 de diciembre de 2013
Autores: Jianming He y Kevin D. Chang
Resumen: Habla sobre todo de resultados audiovisuales, donde al haber muy poco texto es difícil extraer el tema.
Propone calcular una probabilidad de que la búsqueda introducida por el usuario tenga que ver con un tema u otro, y en base a eso devolver y rankear resultados según la probabilidad de que hablen de esos temas, y de que puedan estar dando una respuesta a la pregunta formulada en la búsqueda.
Mi opinión: en ausencia de otras señales, Google podría dar más valor y decantarse por documentos en los que está totalmente seguro de la temática, por lo cual merece la pena hacer todo lo posible por desambiguar nuestras páginas.
Quality (Calidad)
Este es claramente el territorio de Navneet Panda, ingeniero que presta su nombre al conocido update Google Panda.
He encontrado hasta 4 patentes obra de Panda que tratan directa o indirectamente sobre el tema de la calidad de los resultados. Resumo las 3 que me han parecido más importantes, entre ellas las 2 que se sospecha podrían ser base o formar parte del algoritmo Panda.
Por si queda alguna duda de si son relevantes para el proceso de ranking usado actualmente, Google Panda es parte del núcleo del algoritmo desde enero de 2016.
En ese post se cita a un portavoz de Google que dijo:
“Panda is an algorithm that’s applied to sites overall and has become one of our core ranking signals. It measures the quality of a site, which you can read more about in our guidelines. Panda allows Google to take quality into account and adjust ranking accordingly.”
Por supuesto, hay que mencionar este post publicado por Singhal en el blog oficial de webmasters de Google sobre el lanzamiento de Panda, y cómo asegurarse que nuestro sitio cumple con los requisitos de calidad de Google.
Site Quality Score
Número: US9760641B1
Fecha de presentación: 5 de enero de 2012
Concedida: 12 de septiembre de 2017
Autores: April R. Lehman y Navneet Panda
Resumen: esta patente usa dos métodos: uno es poner en relación inversa el número de búsquedas navegacionales de un sitio, con el número de ciertas búsquedas asociadas a un sitio sin ser estrictamente navegacionales (ejemplos: “marca + opiniones” o “marca + fiable”).
Por ejemplo, Amazon es un sitio que recibe millones de búsquedas navegacionales mensualmente, pero el número de búsquedas preguntando sobre la reputación o fiabilidad de Amazon sin duda es bastante más bajo, por lo que su puntuación de calidad será alta.
El otro método pone en relación inversa el porcentaje de casos en los que un usuario hace un clic en resultados de un sitio cuando la búsqueda es claramente navegacional), con el porcentaje en el que sucede lo mismo para búsquedas relacionadas del tipo marca + opiniones, etc.
Mi opinión: que los usuarios te busquen es importante, pero puede ser peligroso si empiezan a hacer demasiadas búsquedas preguntando si eres un sitio fiable. En caso de que ocurra esto, que haya otros sitios dando opiniones sobre ti puede ser favorable, ya que si eres el único que responde a la query “tu marca + opiniones” seguramente tu puntuación de calidad no sea alta.
Esto por supuesto no quiere decir que toda la puntuación del grupo de factores Quality salga de esto, pero puede ser una de las señales individuales que contribuyen a la puntuación total del grupo de Calidad.
Ojo, que tampoco hay que confundir esto con decir que el valor de las puntuaciones que aparecen en sitios de terceros es usado como factor de ranking, como se dijo en algunos blogs tras el Medic Update. Son dos cosas distintas, y el método propuesto por esta patente me parece más fiable para Google (menos manipulable).
Ranking Search Results (1)
Número: US8682892B1
Fecha de presentación: 28 de septiembre de 2012
Concedida: 25 de marzo de 2014
Autores: Navneet Panda y Vladimir Ofitserov
Resumen: propone un método que agrupa urls en base a dos factores: por un lado el número de backlinks “independientes” (no del mismo dominio o conectados entre sí) hacia la página, y por otro el número de queries (búsquedas) que hacen referencia al sitio.
El ratio entre 2 factores determina el grupo al que pertenece cada url, y para cada grupo se asigna un factor de modificación a la puntuación de ranking inicial. Por ejemplo, una url en el grupo de baja calidad podría recibir un alto modificador negativo.
El modificador por grupo varía según el tipo de query introducida por el usuario. Una query puramente navegacional hacia un resultado concreto haría que no se aplicase factor de modificación a ese resultado (pero sí al resto de resultados de la página).
El factor de modificación puede aplicarse no una, sino hasta dos veces sobre un resultado concreto, si el resultado se encuentra por debajo de dos sucesivos umbrales que se aplican para determinar qué resultados deben ser devaluados y cuáles no. Es decir, un resultado podría ser devaluado hasta dos veces sucesivas en los rankings.
Mi opinión: esta es la patente que se cree está más relacionada con la actualización Panda, al menos en su primera versión. Pero hay que tener en cuenta que Panda ha tenido hasta 4 grandes updates, antes de integrarse en el core del algoritmo, y luego puede haber seguido cambiando.
Lo que más me interesa aquí es que si el número de backlinks, aunque estos sean de calidad, crece a un ritmo mayor que el de las búsquedas reales de usuarios sobre nuestro sitio, eso es una señal clara para Google de que algo estamos manipulando.
Importante tener en cuenta que este no es un algoritmo para medir la calidad de nuestro perfil de enlaces, sino que simplemente el volumen de backlinks independientes se usa como medida para establecer unos niveles normales de popularidad de un sitio, en términos de backlinks y búsquedas de marca por parte de los usuarios.
Jugar bien con estos dos factores, de forma totalmente natural, es muy difícil. Por tanto, sería un método poco manipulable y es probable que Google lo siga usando como señal individual dentro del grupo de factores Quality.
Predicting Site Quality
Número: US9767157B2
Fecha de presentación: 15 de marzo de 2013
Concedida: 19 de septiembre de 2017
Autores: Navneet Panda y Yun Zhou
Resumen: esta patente parte de una serie de sitios ya conocidos por Google. Esos sitios tienen ya una puntuación de calidad, que se va a usar como base para calcular la calidad de cualquier nuevo sitio.
Para ello, se analizan los n-gramas (frases de 1, 2, 3… etc. palabras) que aparecen en el nuevo sitio, y con qué frecuencia se repiten. Si el patrón de frecuencias es similar al que tienen los sitios conocidos con calidad alta, el nuevo sitio recibirá una puntuación alta; si la frecuencia es similar a la de sitios con baja calidad, la puntuación del nuevo sitio será también baja.
Mi opinión: este método, o algo muy parecido, sin duda se usa o ha usado para devaluar a sitios que abusan del keyword stuffing y contenido de baja calidad.
Esta es la otra patente que se sospecha describe el comportamiento de Panda en alguna de sus versiones. Para más detalles, podéis leer este post de Bill Slawski sobre esta patente.
El uso de sitios “semilla” cuya calidad o fiabilidad está fuera de duda también se usa en otra patente que trata de calcular la autoridad de una forma diferente al PageRank original, y que explico en este post.
Ranking search results (2)
Número: US9684697B1
Fecha de presentación: 5 de enero de 2012
Concedida: 20 de junio de 2017
Autores: Navneet Panda Vladimir Ofitserov y Kaihua Zhu
Resumen: propone un método para determinar qué sitios deben ser elevados o devaluados respecto a una puntuación de ranking inicial.
Se basa en el porcentaje en que los usuarios vuelven a hacer clic en un resultado orgánico de un sitio, después de haber hecho previamente clic en ese sitio en una búsqueda anterior.
Mi opinión: esta patente evalúa la capacidad de un sitio de generar confianza y retención en los usuarios. Factores como mala usabilidad, mal tiempo de carga, contenido de baja calidad o poco relevante pueden hacer que un usuario no quiera volver a hacer clic en tu sitio, después de haberlo visitado antes desde las serps.
Próximamente: cómo se escogen módulos y se “pinta” la SERP final
Acabo ya, pero falta un aparte del post inicial de Jason Barnard, que me reservo para la segunda parte de este post, sobre cómo decide Google la estructura y los módulos de la SERP. Es decir, si cada uno de los resultados orgánicos debe ser ocupado por un “enlace azul” en el sentido tradicional, o por un módulo o resultado enriquecido, tipo un featured snippet, módulo de noticias, imágenes, etc.
Si quieres leer el original de Jason (en inglés) puedes ir a “How Google Search Ranking Works – Darwinism in Search” (a partir del apartado “Rich Elements Are Candidate Result Sets”).
También podéis seguir en Twitter a Jason Barnard. Este es su blog y este es su fantástico podcast sobre SEO (en inglés, claro).
Conclusión
Creo que como mínimo las revelaciones de Illyes a Jason Barnard sirven para rechazar la típica versión un tanto limitada del SEO, en la cual parece que basta por preocuparse por publicar posts sobre queries con alto volumen, y hacer linkbuilding hacia nuestro sitio.
A nuestra industria le encantan las métricas, es comprensible, porque hay que agarrarse a algo. Pero limitarnos a medir el PA y DA es suicida, dados los grupos de factores que hay en juego, y el hecho de que sólo una baja puntuación en por ejemplo Datos Estructurados, o en Entidades, podría hundirnos.
Entrando ya más en lo que dicen las patentes que tratan sobre Quality y Topicality, no puedo dejar de destacar la importancia que seguramente tienen las búsquedas de marca para calcular diversas señales dentro del algoritmo, y para establecer unos ratios “normales” que muchos SEOs directamente ignoran cuando trabajan en un sitio.
Google siempre está buscando y refinando señales poco manipulables para mejorar sus algoritmos. PageRank es una invención de 1998. Vale que lo sigan usando de manera limitada y muy matizada, pero ¿de verdad crees que puede tener mucho peso dentro del algoritmo una señal conocida desde hace 20 años y que además se puede manipùlar, al menos en la forma en la que se publicó originalmente? Yo no puedo creerlo (otra cosa sería la modificación a PageRank presentada en 2006, mucho menos manipulable).
En fin, cierro ya este pequeño viaje al interior de Google, y espero vuestros comentarios. ¿Habéis encontrado alguna vez comportamientos que podrían estar relacionados con lo que explico en este post, ya sea lo de los grupos de factores, o lo que dicen las patentes? Pues quiero leerlo.

Me quedo con ganas del siguiente capítulo, Juan. Está claro que hay SEO más allá del linkbuilding. Hay veces que te topas con una barrera en las serps que piensas que vas a derribar a fuerza de conseguir más backlinks, y seguro que deberías reorientarte hacia otro aspecto. Gracias por el artículo.
Gracias, David. Sí, prometo que habrá siguiente capítulo. Lo de los featured snippets, etc. tenía que dejarlo fuera porque ya se hacía muy largo y realmente me parecen dos temas diferenciados. Espero publicar esta segunda parte más pronto que tarde. Saludos y gracias por comentar!
Creo en base a mis conjeturas y pruebas que:
El top 10 se ajusta en función del tipo de usuario que hace la búsqueda.
En función de si ya ha hecho búsquedas relacionadas con ese tema o si no las ha hecho. En cada caso mostraría unas serps que según Google, han respondido mejor a lo que el usuario buscó. Incluso en función de la ubicación del usuario no es lo mismo buscar qué ver en Gijón (allí ya necesita moverse por la ciudad), estando allí. Que buscar qué ver en Gijón desde Jaén. (busca planificar).
Ya conoces tu mi web…
Por otro lado te lanzo una cuestión. Cuando dices «el numero de queries que hacen referencia al sitio» ¿te refieres a las búsquedas de marca + una keyword? En Plan «Useo artículo de tráfico»
Efectivamente, puede ser sospechoso que nuestro sitio crezca en enlaces cuando apenas es relevante nuestra marca.
Para hacer relevante, no dudemos en el marketing tradicional…. (no digo un anuncio en tv, pero hay muchos otros métodos).
En la parte de Actualidad del punto 2 (Disculpa por volver arriba otra vez), a mi me funciona bien, trackear las keywords que bajan e incluir algo de información adicional para sanar ese contenido ligeramente. A veces sube a veces no, pero intento mantener los contenidos lo más actualizados posible.
Gracias por la recomendación del podcast.
Un placer leerte Juan.
Hola Rafa, lo que cuentas según tu experiencia se acerca bastante a lo que he dejado sin adaptar del post de Jason Barnard, la parte de cómo los módulos ganan presencia en una serp según Google entiende el user intent. Puedes leerlo en el post de Jason, y por mi parte yo ya concretaré más cuando lo publique.
«Número de queries que hacen referencia al sitio» -> en el caso de esa patente (US8682892B1) son todas las que incluyan la marca, incluso las meramente navegacionales (como por ejemplo amazon) y también las de tipo «marca + keyword» o «marca + opiniones». Entiendo que si incluyen la marca, cuenta.
Lo que cuentas de actualidad / freshness sin duda es buena táctica. Se nota que haces tus deberes y aplicas todo lo que puedes a tu sitio. 😉 Un abrazo y muchas gracias por comentar, Rafa!
Hola Juan,
En mi caso si que tuve un proyecto en el que estaban los 7 grupos razonablemente bien, a excepción de las entidades, donde encontramos un problema.
Un par de semanas después de solventarlo, la web empezó a rankear bien, aunque no eran KWs excesivamente competidas.
Además, no tengo recuerdo de haber hecho ninguna otra cosa por el medio, ni tan siquiera linkbuilding, pero realmente nunca sabremos a ciencia cierta si solventar ese error con las entidades fue lo que hizo a la web subir en las SERPs.
Con ganas del siguiente capítulo.
Genial como siempre.
Muchas gracias.
Un saludo.
Qué bueno, Saúl. Muchas gracias por compartir ese caso, suena a que encaja totalmente con la teoría. Yo por mi parte tengo algún caso de web en la que no tocamos el linkbuilding ni con un palito desde hace más de 3 años (nos marcamos otras prioridades por preuspuesto y por otras razones) y sin embargo ahí está, dando guerra en el top para muchas keywords competidas. Pero la web tiene búsquedas de marca y es fuerte en otros apartados. Saludos!
Wow información acojonante!
Leyendo esto dan ganas de volver a usar ctrbox y manipular búsquedas de marca que no?
Hola, Iván! Hombre, por experimentar que no quede. Pero según las patentes que he analizado (otras puede que digan otra cosa) en realidad sólo necesitas «controlar» el factor búsquedas de marca si estás creando artificialmente autoridad por medio de enlaces.
Para webs sin enlaces, porque son nuevas, esto no sería necesario, y para webs con enlaces y con búsquedas de marca que se dan de manera natural, tampoco.
Saludos y gracias por comentar!
Esto explica el porque a veces el SERP cambia por que le da «la gana».
Si te sirve para añadir algo de hipótesis, pienso que la puntuación «tope» es un valor relativo a la SERP, es decir, si todos tienen quizás una fuerza de enlace baja, por mucho que lo subas Google le interesa limitarlo. La razón es sencilla, (Algo que también he visto en Ads) es que Google le gusta jugar al Robin Hood, a él no le interesa que un bicho conquiste el mercado, le interesa repartirlo para que todos paguen o sigan currándose el SEO.
Es una teoría, meramente.
Muchas gracias por tu comentario, Narciso. Me gusta bastante tu teoría y yo también he pensado alguna vez que el número de enlaces puede estar normalizado, de forma que pasada cierta cantidad, cuantos más consigas, menos mejoras tu ranking. Por otro lado, alguna vez desde Google han dicho, a través de Gary Illyes, creo, que hay ciertas búsquedas en las que los enlaces apenas cuentan, o no cuentan nada, para el rankeo. Gracias y saludos!
Chapó. Gran artículo, me quedo con ganas de leer más
Muy buena explicación. A qué llamas «entidades» que factor sería?
Excelente artículo, Juan! Muchas gracias por compartirlo!
Genial si escribes uno con tu opinión relacionad a los featured snippets 🙂
Saludos!
En mi experiencia, Google hace lo que le sale de la entrepierna. En cuanto a SEO: tengo monitorizadas varias palabras clave en distintos dispositivos y en distintas localizaciones. Las diferencias llegan a veces hasta más de 20 posiciones. ¿Porqué? Cada uno que saque sus conclusiones. En cuanto a Adwords, por mucho que uno se saque certificaciones, optimice el nivel de calidad de la página, optimice anuncios, pujas y varias cosas más, las rotaciones de anuncios en ciertos nichos de negocios estacionales, por mucho que digan los de Mountain View que no es un hecho que beneficia al gigante.
Hola, gracias por tu comentario, pero si he entendio bien lo que dices, siento discrepar totalmente. Voy a tratar de explicarte por qué.
1. Respecto a los cambios de hasta 20 posiciones según dispositivo o ubicación, y asumiendo que no sean keywords con intención local, en cuyo caso la diferencia estaría totalmente justificada, creo que es parte del fenómeno que dede fuera solemos llamar Google Dance, y que tiene que ver más con los miles de tests que Google realiza cada año en su sistema de ranking y re ranking, y también con cuestiones técnicas del sistema de indexación (el index no se actualiza entero al mismo tiempo, sino que se va propagando y actualizando por cada data center, y por tanto en un determinado momento desde una ubicación puedes ver los rankings más actualizados que desde otra). Más info aquí: https://webmasters.googleblog.com/2019/08/when-indexing-goes-wrong-how-google.html
2. En cuanto a Google Ads (antiguo Adwords) las rotaciones de anunciantes en un término sólo pueden darse cuando hay demanda, es decir, cuando más de un anunciante está pujando con el presupuesto, CPC y niveles de calidad mínimos para aparecer por esa keyword. Si no hay demanda de más de un anunciante, esto no puede darse. Por tanto, aunque obviamente beneficie a Google que ocurra, no es algo que ellos manipulen externamente (no pueden crear demanda donde no la hay), y de hecho tiene todo el sentido del mundo que ocurra en los nichos estacionales en los momentos de máxima demanda.
Gracias de nuevo por comentar y saludos.