

¿Qué es Safecont y en qué se diferencia de otras herramientas SEO?
¿Otra herramienta de SEO? No, Safecont es una herramienta bastante distinta a lo que estás acostumbrado. Te lo aseguro yo, que soy un tool-adicto y las he probado todas.
En primer lugar, Safecont no se limita a revisar un checklist para decirte si tu sitio cumple una serie de buenas prácticas. Tampoco se limita a reproducir la respuesta de cada URL, almacenando todos los datos de esa respuesta (que no es poco).
No. Safecont te avisa de las posibilidades de tu sitio de caer en un peligro muy concreto: Panda. Y quien dice Panda, dice todos los updates no oficiales (llámense Phantom, Fred o unknown update) que pueden darle un pescozón a tu sitio por thin content, contenido duplicado, una arquitectura débil y todas esas cositas que protagonizan casi cualquier auditoría SEO.
Dicho de manera sencilla, analiza el grado de calidad de tu contenido y la fuerza de tu arquitectura, dando métricas concretas y segmentando tu sitio por zonas, de menor a mayor peligrosidad (clusters de páginas que muestran unos niveles parecidos de peligro).
Lo que un consultor SEO está acostumbrado a hacer en una labor bastante manual, que puede llevar horas y horas si el sitio es muy grande, Safecont lo hace en unos pocos minutos. Y eso es lo que yo pido a una herramienta SEO, que me facilite el análisis y sobre todo, que me ahorre tiempo.
Aviso: este post te puede interesar incluso si estás convencido de que Safecont no es para ti o se sale de tu presupuesto. Hablo de varios conceptos que te pueden ayudar a comprender y encontrar errores de contenido y estructura en tu sitio, y hay cosas que puedes poner en práctica aunque no uses Safecont.
Cómo analiza Safecont la calidad de un sitio
El rinoceronte de Safecont es así de potente porque está dopado con Big Data y machine learning.
Aunque ellos explican todo esto muy bien en su web, yo voy a tratar de explicarlo sin tecnicismos. Puede que no todo lo que voy a decir sea 100% correcto (César Aparicio me perdonará), pero es para que cualquiera pueda entender por qué es una herramienta tan efectiva.
Safecont tiene una gran base de datos (no tan grande como Google, claro, pero respetable en cualquier caso) en la cual analiza las posiciones en Google de las páginas y ciertas características de su contenido y estructura.
Tras analizar millones y millones, y fijándose en estos rasgos que ha elegido, puede extraer unos patrones de probabilidad de que una página posicione bien, o por el contrario, sea hundida por el Panda.
Por poner un ejemplo y simplificando mucho, Safecont ha encontrado que cuando un sitio tiene un alto porcentaje de páginas cuyo contenido es casi idéntico o muy similar, sus posiciones se hunden.
Pues a continuación busca este tipo de problemas en tu sitio y asigna una probabilidad de que te veas perjudicado en Google por esta causa, tanto a nivel de sitio, como de clúster (grupo de páginas con rasgos comunes), como a nivel de url.
Y así con otros problemas, como thin content, duplicación externa, mala distribución del PageRank interno, etc.

Con los resultados que te da Safecont en la mano, está chupado detectar qué páginas son las que hay que mejorar (o eliminar) de tu sitio, para que la puntuación global de calidad de tu sitio crezca, y se vaya alejando poco a poco el fantasma de Panda y cualquier otro problema causado por los updates de calidad de Google.
Todo esto lo digo ya con conocimiento de causa: son ya muchos los sitios, completos o en folders, que he pasado por el rinoceronte, y una y otra vez he encontrado que el grado de coincidencia entre las páginas que Safecont da como más saludables del sitio, y las que en efecto posicionan mejor y reciben más tráfico, es ciertamente alto (y viceversa, una mala puntuación suele coincidir con baja visibilidad en Google).
Hecho bastante sorprendente (para bien), si tenemos en cuenta que Safecont analiza tu sitio sin conectarse a Analytics o Search Console, ni escrapear siquiera las SERPs, como hacen Ahrefs o Sistrix. Sencillamente, analiza tu contenido y estructura, compara con su base de datos, y otorga una puntuación.
De la misma forma, suele darse que analizando sitios similares en cuanto a tamaño y temática, el de mayor puntuación en Safecont tiende a coincidir con el de mayor visibilidad orgánica, y si analizamos segmentos dentro de un sitio (como blog versus tienda online), he observado que en general suele darse lo mismo.
Por supuesto, tampoco esperaba, ni debes esperar tú, una coincidencia al 100% entre puntuación de Safecont y tráfico orgánico real, ya que hay muchos factores que están fuera de la ecuación, principalmente la competencia orgánica y el volumen de las keywords implicadas, el SEO off page, que hayas acertado o no con el Title de una página…
Pero si pensamos que con una muestra alta de páginas y sitios esos factores totalmente externos al análisis de Safecont tienden a equilibrarse entre sí, tendremos que si Safecont hace bien su trabajo el ratio de acierto debería ser bastante alto. Y en mi experiencia lo es.
Vamos a verlo todo con ejemplos concretos. Recuerda que si quieres probar la herramienta, Safecont ofrece un modo trial gratuito.
Auditando un sitio con Safecont
En la pantalla inicial de Google, eliges el dominio que quieres analizar, y especificas si lo vas a analizar todo, o en parte. Puedes usar las mismas reglas que se usan en el robots.txt para decirle a Safecont qué páginas, folders o subdominios de tu sitio puede rastrear y analizar, y cuáles no.
Así, en lugar de analizar todo tu sitio, puedes limitarte a analizar el blog, o el folder de la versión en inglés, o todo el contenido de una categoría concreta.
Desde esta pantalla también puedes decidir si vas a activar la detección de contenido duplicado externo o no (tiene un coste adicional, salvo que estés en el plan más alto, el de Agencia, que ya lo incluye en el precio). Por el momento, yo no he probado esta funcionalidad de duplicidad externa, por lo que en mi reseña no hablaré nada de esto.
Dashboard o visión general
Una vez acabado el rastreo (que suele llevar entre 10 y 30 minutos, si no pasas de las 1000 URLs) accedes a una pantalla de visión general o dashboard que te informa de la situación del sitio.
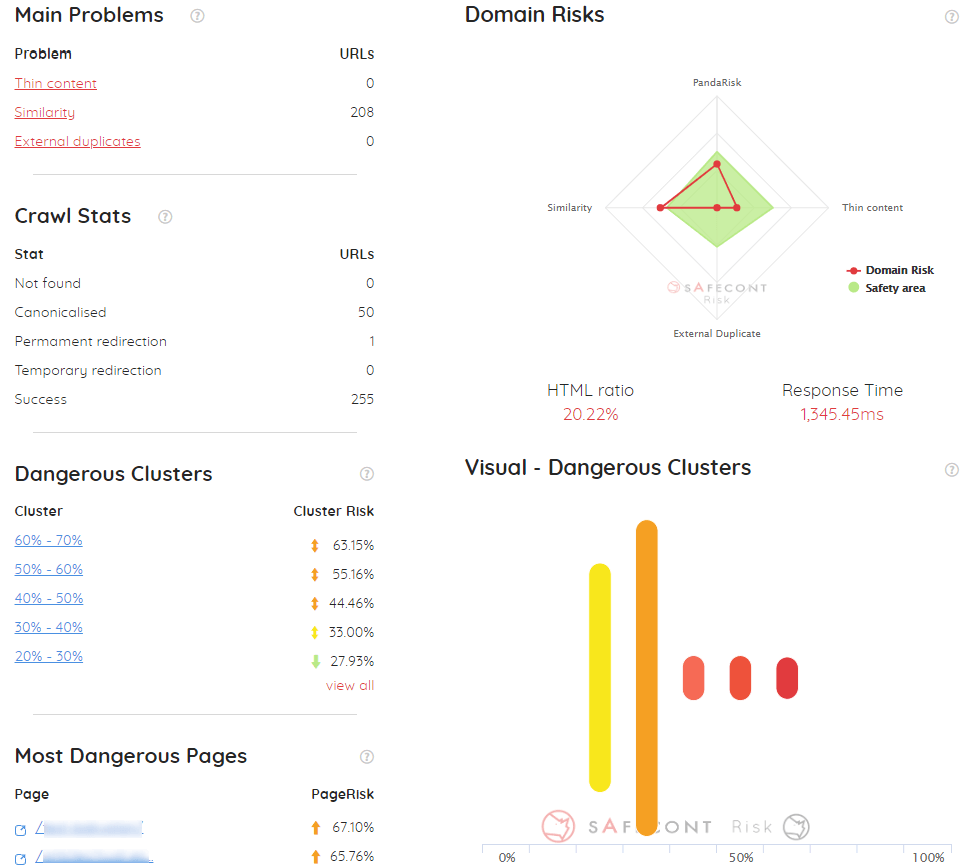
De un vistazo, tendrás:
- La puntuación general del dominio (lo que Safecont llama PandaRisk)
- La puntuación para los 3 Risks o problemas principales (Thin Content, Similarity y External Duplicates)
- Las estadísticas del rastreo (parecido a lo que sería Crawl Overview en Screaming Frog, pero más escueto)
- Los clusters más peligrosos
- Un listado de las páginas más peligrosas
Aparte de la puntuación de PandaRisk (con un rinoceronte que se va poniendo más rojo y cabreado según sube el peligro) lo que más llama la atención en el dashboard son las visualizaciones de Risks y clusters, que al principio te parecerán un poco raras, pero enseguida se te harán sencillísimas de entender para cada análisis.
Visión general de URL
Si haces clic en cualquier de las urls marcadas como de alto riesgo, pasarás a una pantalla donde tendremos la puntuación individual para todas las métricas de Safecont: PandaRisk, Thin Content, Similarity y External Duplicates.
También podrás ver datos de tráfico orgánico de esta url, si es que tienes el proyecto conectado a Analytics.
Además, tienes un enlace para acceder a las URLs más similares en cuanto a contenido que hay en el sitio.
Pero para mí lo más importante que puedes encontrar en este informe es el análisis TF-IDF.
Análisis TF-IDF de URL
TFIDF o TF-IDF es un método estadístico usado en Information Retrieval para determinar la probabilidad “natural” de que una palabra aparezca en una página, dada la frecuencia con la que esa palabra aparece en un cuerpo de datos más grande, que en el caso de Google sería su index o más bien todo su universo de páginas rastreadas y analizadas.
Si en tu página un término aparece con más frecuencia de lo normal, entonces Google puede considerar que tu página es un documento importante en referencia a ese término. Pero, ojo, que un TF-IDF demasiado alto, muy por encima de la probabilidad normal de que aparezca ese término también puede ser negativo.
En base a este método, para cada url veremos las palabras que aparecen con más frecuencia en la página, ordenadas de más a menos TF-IDF. De esta manera puedes darte cuenta si un término que es relevante para el tema de esta página no aparece mencionado lo suficiente.
Por último, es muy interesante el último informe:
Null TFIDF
Aquí verás las palabras que aparecen mencionadas en TODAS las páginas de tu sitio, con lo cual para esas palabras se elimina virtualmente cualquier efecto de tener un TFIDF alto para esa palabra en esta url.
Es decir, si una palabra aparece mencionada en todas las URLs de un sitio, el TFIDF de ese término cae automáticamente a un valor de 0, con lo cual disminuye mucho la posibilidad de posicionar para esa palabra.
Por lo tanto, mucho ojo a las palabras que aparezcan en esta lista. Que yo sepa, no hay ninguna otra herramienta SEO que proporcione términos con null TF-IDF para una página.
Y antes de acabar con esta parte, un aviso: no creo que sea bueno obsesionarse con el TF-IDF, más allá de identificar qué términos que no se han usado en absoluto, o qué términos quizá por descuido se están usando en todo el sitio y no deberían.
No debes pensar que por tener para un término concreto una puntuación de 7.20, mientras que la página de tu competencia sólo tiene un 4.50, automáticamente tú deberías rankear mejor para ese término.
Primero, porque hay otros factores en juego, y segundo, porque es posible que ambas puntuaciones sean vistas por Google como “suficientemente buenas” para rankear para ese término, y tener un 7 no aporta nada extra sobre tener un 4.
Como no estamos dentro de Google no lo sabemos, y por eso recomiendo, como siempre hago, no caer en la obsesión.
Si queréis profundizar en este tema, os recomiendo un par de posts publicados en el blog de Safecont:
TFIDF: en búsqueda de la normalidad
Midiendo la calidad de una página mediante el TFIDF
Risks
Seguimos con los informes de Safecont. La pestaña Risks nos va a dar un vistazo más en profundidad de los problemas que afectan al sitio, y en qué proporción.
Los “sospechosos habituales” con los que trabaja Safecont son la duplicación interna (a la que Safecont llama Similarity), el Thin Content y la duplicación externa.
Aquí veremos una puntuación para cada una, junto con una lista de las páginas con mayor puntuación de peligro en cada área.

Clusters
Desde este informe, podemos “atacar” el análisis de nuestro sitio por partes, en lugar de por urls individuales.
Safecont divide el sitio en clusters de peligro según los 3 criterios que hemos visto ya: Similarity, Thin content y duplicación externa.
Para cada problema, tendremos nuestro sitio dividido en 10 franjas o clusters, de más peligro a menos. Así, tendremos el clúster en el que se ubican las páginas con una Similarity del 90% al 100%, el clúster con Similarity de 80% a 90%, etc. Y lo mismo para los demás problemas.
Es una forma excelente de priorizar el trabajo en las distintas áreas, y lo tienes ya todo hecho para ti.
Similarity (contenido duplicado interno)
Vamos con uno de los problemas que me encuentro más a menudo al auditar sitios. El contenido duplicado interno es mucho más común de lo que la mayoría piensa, y puede ocurrir tanto por no controlar las urls creadas por nuestro CMS (esto es lo más frecuente en sitios de todo tipo), como por no crear suficiente contenido único para cada url (especialmente frecuente en las fichas de producto de un ecommerce).
Lo que importa es que Googlebot acabará encontrando porcentajes demasiado altos de similitud entre el contenido de varias páginas de tu sitio, y ya estás bajo la amenaza de un filtro por contenido duplicado; o peor, de un filtro por contenido de baja calidad, si el porcentaje de páginas con problemas de duplicación dentro del sitio es lo suficientemente alto.
En este informe de Safecont encontrarás tanto los distintos clusters de porcentaje de duplicación interna en los que ha dividido tu sitio, como una lista de páginas, ordenadas por su porcentaje de duplicación. Esta tabla te dirá también cuántas urls del sitio tienen similitud con cada url de la lista.
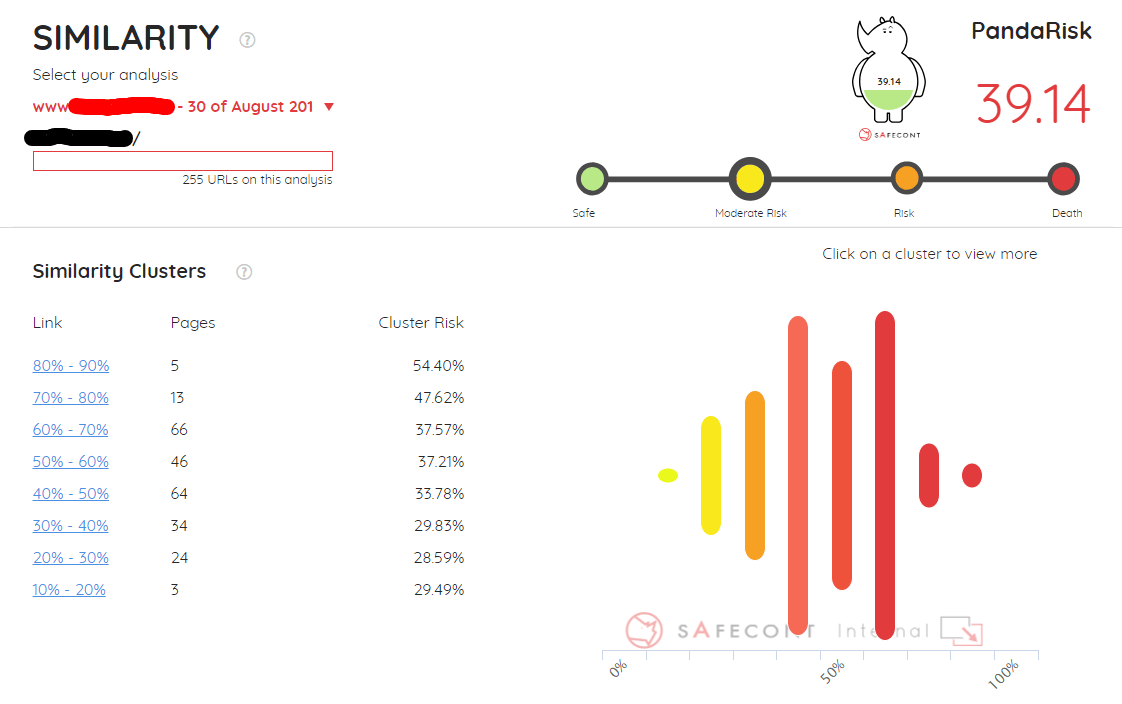
Si haces clic en el pequeño rinoceronte junto a cada url, pasarás a la visión general de url, donde además de lo que comenté antes, tienes un informe muy útil (Similar Pages With This), donde puedes acceder a la lista de todas las urls con que guardan parecido con esta.
Mi forma de trabajar dentro de la pestaña de Similarity sería ir analizando las urls de mayor peligro, bien en el total del sitio o por clusters si el sitio es demasiado grande, detectando por qué se produce la duplicidad.
Si es un tema técnico o es el CMS el que los crea, iría solucionando esos problemas y descartando urls ya solucionadas de la lista.
Si el problema se produce por categorías o fichas de producto sin apenas contenido único, las iría añadiendo a una lista de páginas en las que necesito mejorar o crear más contenido. Y así hasta que haya analizado todas, o al menos haya llegado a un nivel donde el porcentaje de duplicidad no debería darme problemas.
External Duplicate
Esta parte de la herramienta (que lleva un coste adicional por uls) la tengo inédita, por lo que no os puedo contar nada.
Me imagino que trabaja de una manera similar a herramientas como Siteliner o Copyscape, a juzgar por este post del blog de Safecont donde analizaban la tesis de Pedro Sánchez en busca de plagios.
Thin Content
Otro de los caballos de batalla, si quieres estar a salvo de Panda, Phantom y otras criaturas de Google.
Por lo que he podido comprobar, Safecont avisa de problemas de thin content en todas las urls cuyo contenido total está claramente por debajo de la media del sitio.
Es decir, no parece haber una barrera en términos absolutos, como por ejemplo 300 palabras, que determine si una página va a estar libre o no de la amenaza de thin content, sino que el criterio parece ser siempre relativo al sitio.
Además, es muy posible que haya más factores en juego que la extensión de contenido, como por ejemplo distribuciones del TFIDF pobres o demasiado parecidas entre sí, etc.
Tal y como he indicado en el apartado Similarity, aquí tenemos el thin content presentado por clusters y por páginas, de forma que podemos elegir fácilmente por donde empezar a solucionar el problema.
Es interesante destacar que las páginas con un ThinRatio menor de 33.33% no serán incluidas en la cuenta de urls con Thin Content en el informe Main Problems que aparece en el Dashboard. Por lo tanto, si sólo tenemos páginas con Thin Ratio por debajo de ese umbral, Safecont nos está diciendo que ese problema no es prioritario.
Es decir, no es necesario llegar a tener un ThinRatio de casi 0 en todas las páginas de nuestro sitio. De hecho, esto es prácticamente imposible, ya que al estar en relación al total del sitio, siempre va a haber un pequeño porcentaje de páginas más thin que otras. Pero mientras el ThinRatio individual de cada url se mantenga por debajo de 33,33%, estaremos bien.
Semantic
Quizá uno de los apartados más complejos de Safecont, y al que reconozco que todavía tengo que sacarle todo su jugo.
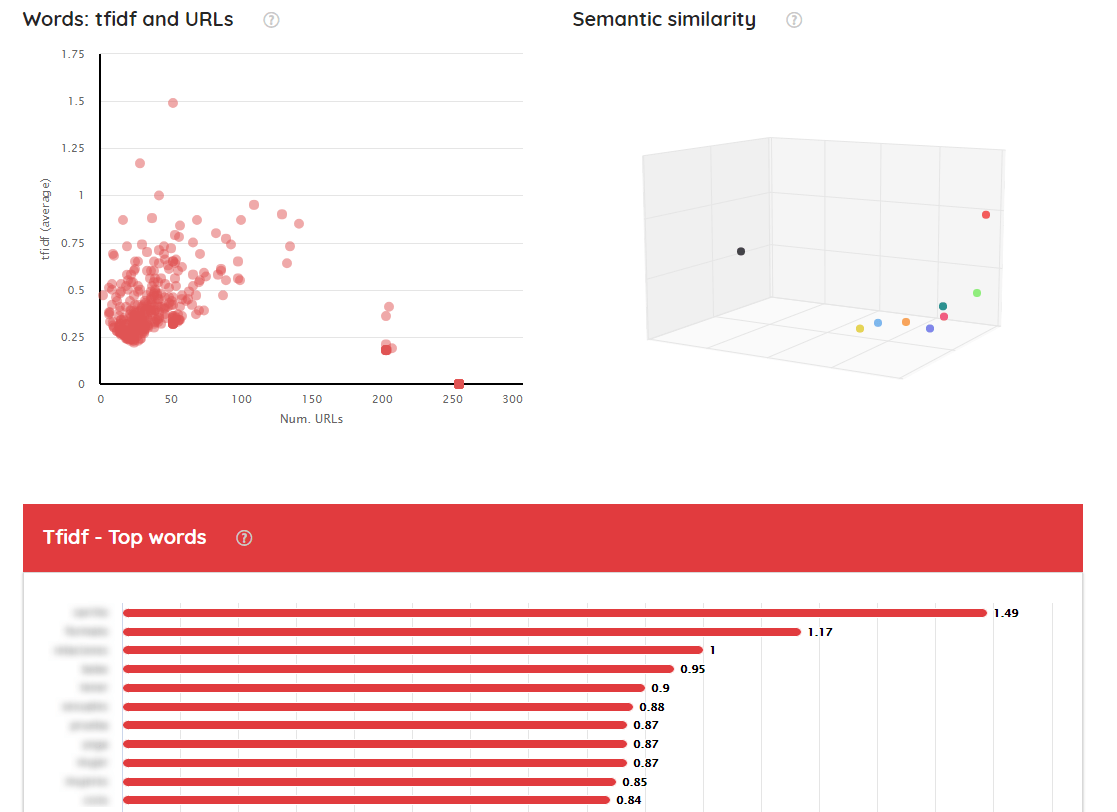
Aquí encontramos una serie de visualizaciones:
- Palabras. Analiza su TF-IDF a nivel de sitio (eje vertical), y el número de urls en el que aparece cada una (eje horizontal).
- Similitud semántica y clusters semánticos. Grupos de urls que tienen un gran número de palabras en común.
- TF-IDF: a diferencia del TF-IDF para cada página, aquí vemos la puntuación de cada palabra en cuanto a TF-IDF considerando todo el sitio (o parte analizada del mismo) como un todo.
Pages
Una lista de las páginas de tu sitio, ordenadas según su PageRisk, y con datos sobre las otras métricas individuales de Safecont:
- PageRank (interno, ver el siguiente apartado)
- Similarity
- Duplicate External
Si te descargas el informe Pages (lo cual recomiendo hacer para cada proyecto que tengas), podrás jugar y ordenar las págians según la métrica que más te interese, incluida ThinRatio, que no está disponible directamente en el informe Pages, sin entrar en el informe de url individual.
Architecture
El contenido no lo es todo, y sin una buena estructura o arquitectura web, puedes estar debilitando la calidad de tu sitio a ojos de los buscadores, aparte de que el Pagerank o link juice no fluirá debidamente de unas páginas a otras.
En este apartado el rinoceronte nos muestra:
- Un listado de urls por niveles de profundidad de enlazado, similar a lo que podemos sacar de Screaming Frog, pero con el añadido de que tenemos una puntuación media de PageRank para nivel (Level Strength)
- Una visualización de las relaciones de enlazado interno de la página, donde veremos representadas las páginas con mayor PageRank interno (más alto cuanto mayor es el tamaño de la bola) y cómo se enlazan entre sí. No es la visualización más clara de Safecont.
- Un listado de páginas, de acuerdo a su PR interno. Si te lo descargas tendrás todas las métricas de esta sección (PageStrength, Hub, Authority) para cada página del sitio.
- Un listado de los principales Hubs del sitio, junto con su puntuación de Authority (a continuación explico estas dos métricas)
- Los anchor text que más se repiten en los enlaces internos del sitio

El concepto más original, con respecto a otras herramientas que también analizan la estructura de un sitio, es el de Hubs y Authorities.
La idea de que la web se divide en dos tipos de páginas, las que enlazan a otras (Hubs) y las que son enlazadas (Authorities), viene del algoritmo HITS, desarrollado por Jon Kleinberg casi al mismo tiempo que el PageRank de Larry Page.
Según HITS, los Hubs son páginas “directorio” o distribuidoras, que sirven para encontrar otras con autoridad, y por tanto es donde los buscadores deben acudir primero para localizar las Authorities, las que realmente interesan al usuario que ha hecho una búsqueda.
Este modelo, que muy probablemente ha sido adaptado o incluido de alguna manera por Google, nos puede ayudar a estructurar mejor nuestra web.
En Safecont, la puntuación de Hub de una url va en función del número de páginas del sitio a las que enlaza. Mientras que la puntuación Authority de una url depende del número de páginas que estén enlazando a esa url concreta.
Ciertas páginas pueden ser al mismo tiempo Hubs y Authorities, como por ejemplo la home (porque está enlazada desde todas las páginas del sitio y suele actuar como directorio para llegar a las páginas más importantes del sitio).
Las categorías principales de un ecommerce en general deberían puntuar alto tanto para Hub como Authority, y las páginas que consideremos más importantes en un sitio nunca deberían puntuar bajo en Authority (ni tampoco en PageStrength).
Por último, las páginas con la puntuación más baja de Hub en tu sitio serán seguramente aquellas que no contengan ningún enlace interno, aparte de los enlaces en menús que se repiten en todo el sitio. Un buen lugar por el que empezar a mejorar el enlazado interno de tu sitio.
Crawl Stats
Esta es la parte más similar a un crawler tradicional como Screaming Frog, OnCrawl, etc. Aquí verás el estado de tu sitio en cuanto a rastreo (errores 404, redirecciones…) e indexación (páginas con noindex, canonicalizadas, etc).
También tendrás una clara visión de los niveles de enlazado interno y de los tiempos de respuesta de cada una de tus páginas.
Aunque este apartado no es el punto fuerte de Safecont, es una información que se agradece tener, y que a algunos usuarios les ahorrará el tener que depender de un crawler
Mi opinión sobre Safecont: ventajas respecto a otras herramientas
Bien, llega el momento de la verdad. Ya he dejado claro que Safecont es una herramienta potente y que no se queda en la superficie, sino que aporta un valor clarísimo en capacidad y velocidad de análisis.
¿Es para todo el mundo? Quizá no… El coste puede ser a priori una barrera, aunque como he dicho desde el principio, Safecont es una herramienta que claramente le ahorra tiempo a los consultores y equipos SEO que trabajen con regularidad con webs con problemas de contenido duplicado y/o thin content. Este tipo de problemas en tiendas online y webs grandes con mucho contenido son de lo más frecuente.
En mi caso particular, es una gran parte del trabajo que hago día a día, tanto auditando nuevas webs que llegan a mis manos, como en webs, generalmente de ecommerce, en las que trabajo durante varios meses mejorando todos los problemas de SEO que hayamos identificado.
¿Qué es la calidad de contenido y cómo podemos medirla?
Por último, quiero destacar el hecho de que Safecont ponga en números algo que puede parecernos tan subjetivo como la “calidad” del contenido. Para mí, uno de los mayores aciertos de esta herramienta.
La calidad del contenido es uno de los problemas recurrentes del SEO. Pásate por un foro cualquiera del sector y antes de diez minutos te habrás encontrado varias veces la queja de un webmaster diciendo que su contenido es de “más calidad” que la competencia y que sin embargo Google castiga a su sitio y premia a los rivales.
Pero, ¿quién mide la calidad, y sobre todo, cómo? ¿La mides tú? ¿La mides página por página, o tienes algún sistema para medir la calidad del sitio entero? Y, sobre todo, ¿has elaborado alguna métrica para poder concluir que tu contenido es, efectivamente, superior al de otros?
Pues eso es lo que te brinda Safecont. Podrá acertar más o menos, pero al menos es un sistema objetivo para comparar la calidad de varios sitios, folders o páginas, y no es un mero “mi contenido tiene mucha calidad, porque no lo he copiado de ningún sitio y porque cada post pasa de 1500 palabras”.
Estoy harto de ver bloggers que se curran un montón de posts larguísimos sobre un tema, sin caer en que, a ojos de una máquina, quizá muchos de sus posts son demasiado parecidos entre sí. Quizá están canibalizando una y otra vez las mismas palabras clave, o usando siempre una serie de términos en todos los posts, confundiendo a la máquina que tiene que desambigüarlos y asignarles puntuaciones de relevancia para ciertas queries.
Me gustan tanto las métricas de Safecont que creo que la industria del SEO se beneficiaría bastante si estas, u otras similares, se convirtieran en un estándar, tal y como ahora son PA o DA. El problema que le veo a DA y PA es que como baremos dentro del SEO son bastante inexactas y además sólo tratan de hacer una aproximación al PageRank, dejando fuera todos los demás factores que Google tiene en cuenta.
El PandaRisk Score, en lo suyo (contenido y On Page) es bastante más preciso, y además más completo, ya que no estima un sólo factor aislado, sino una confluencia de factores.
Apartados a mejorar
Safecont es una herramienta bastante joven en el panorama y lógicamente aún tiene algunos aspectos que pulir o mejorar.
Personalmente, echo de menos la posibilidad de comparar rastreos fácilmente, ya sea dentro de un mismo proyecto, o dominio frente a dominio. E incluso me parece un poco limitada la capacidad de exportar los datos fundamentales de cada rastreo (se puede exportar a PDF, pero a mí me gustaría a Excel o CSV).
Otro feature que me encantaría sería la posibilidad de rastrear listas de urls, tal y como es posible en Screaming Frog, al menos para la parte de duplicación de contenido.
Mi nota
Para terminar: ¿qué nota le pongo a la herramienta? Sobresaliente, y no llego a matrícula de honor, porque sé que aún puede mejorar, y lo hará (parece que pronto llegará una nueva función llamada Link Optimizer, en cuanto lo haga prometo actualizar el post).
Por todo lo que he contado hasta el momento, no tengo dudas. Safecont ya es parte de mi arsenal de herramientas SEO, de hecho pasó a formar parte del mismo desde el primer día en que la probé, y no la cambio por nada de lo que hay en el mercado (realmente no tiene competidores directos, y si acaso, sólo algunas de sus funciones pueden hacerse en parte con otras herramientas).
Si te dedicas seriamente al SEO te recomiendo, como mínimo, darle una oportunidad con el plan de prueba gratuito que ponen a tu disposición.
Eso es todo. Si tú también has probado ya la herramienta, espero tus comentarios.

No se si agradecer este articulo ya que estoy haciendo una guía de clinicas dentales y los resultados son terribles ya que no puedo agregar demasiado contenido único mas allá de el nombre y servicios que presenta cada clínica, deberé revisar alternativas ya que los resultados son muy malos.
La herramienta me parece de clase A.
Saludos
Sigo repitiendo y este artículo me lo confirma que sin duda esta herramienta es una de las mejores del mercado respecto al panorama que facilita frente una auditoría es increíble.
Muchas gracias por este articulo muy bien detallado.
Saludos!
Wuao, que bueno que hablas de esta herramienta, hasta hora la veo y definitivamente me ha parecido fabulosa, que buen post, lo hablas de una manera clara y sencilla voy a revisarla para ver cómo me va.
Hola Juan:
No conocía esta herramienta y, tal como lo comentas, se sale de lo convencional. Me ha gustado mucho el formato con el que presentan las métricas y el detalle con el que muestran las páginas con errores y su respectivo nivel de riesgo.
Algo que no me ha quedado muy claro es el gráfico de la arquitectura del sitio, si en algún momento puedes profundizar un poco más acerca de este tema por favor, estaría muy agradecido.
Si bien es cierto que desde hace tiempo te sigo en Twitter, ahora te estoy siguiendo la pista más de cerca (me gusta mucho el SEO para ecommerce) en las plataformas donde publicas contenido o participas como invitado.
Por ejemplo, en el Podcast de Planeta M he aprendido mucho acerca de las palabras clave y cómo analizar las intenciones de búsqueda, ha sido un episodio muy entretenido con invitados de lujo. Muchas gracias.
Saludos!
Hola Camilo, gracias por tu comentario y me alegro de que sigas mis contenidos.
Respecto al gráfico de arquitectura en safecont, hay 2, uno un poco más convencional en el que ves el número de URLs por nivel de rastreo o enlazado interno, y la fuerza media que le da Safecont a ese nivel (haciendo un promedio de PageRank interno), y luego otro gráfico donde aparecen las páginas representadas como nodos de un grafo de enlaces, y las aristas son las relaciones de enlazado entre esas páginas. Aparecen centrales y con mayor volumen las páginas más enlazadas del sitio, que acumulan mayor pagerank interno, por eso es fácil que veas las páginas presentes en el menú principal de tu web, aunque puede haber casos de páginas muy fuertes en la estructura que no estén en el menú. Con esta visualización puedes saber de un vistazo cuáles son las más importantes en la estructura.
Saludos,
Juan