

¿Es esta la patente detrás de EAT y el Medic Update? Representaciones de vectores para clasificar sitios por temática y autoridad
El tema más debatido en la comunidad SEO desde el lanzamiento del llamado Medic Update en agosto de 2018 es cómo mide Google una suma de conceptos englobados como EAT en su guía para evaluadores de calidad. EAT son las siglas de Expertise, Authoritativeness, Trustworthiness, que podríamos traducir a español como “Experiencia, Autoridad, Fiabilidad”.
En este post voy a analizar una patente de Google concedida recientemente (el 13 de febrero) pero presentada originalmente en agosto de 2018, y que describe un sistema basado en vectores para representar sitios web, y el uso de redes neuronales para clasificar esos vectores en grupos de sitios según su temática y grado de autoridad en ese tema.
Es un método que le podría servir a Google para separar a los sitios con contenido experto del resto en temáticas sensibles (las llamadas temáticas YMYL, “Your Money, Your Life”). De hecho, la patente alude hasta en 8 ocasiones a la temática “Health” (salud) y pone un ejemplo específico de distintos grados de autoridad en esta temática.
Como siempre, el mérito del avistamiento de esta patente corresponde al gran Bill Slawski, que el pasado 21 de febrero ya publicó un primer análisis de esta patente.
Me extraña el relativo poco revuelo que ha generado el descubrimiento de esta patente en la comunidad SEO (especialmente en español), y por ello he decidido comentarla y compartir mi propio análisis.
Vaya por delante que, como suele ser el caso con cualquier patente de Google, no tenemos evidencia de que este sea realmente el sistema detrás del core update de agosto de 2018. Y el hecho de que algo haya sido patentado por Google tampoco garantiza que esté teniendo aplicación práctica en el buscador.
Pero la coincidencia de fechas, y el hecho de que describa fenómenos y efectos muy parecidos a los observados en el Medic y otros core updates sucesivos, hace que en mi opinión sea muy importante tener en cuenta o al menos conocer esta patente.
Vamos a ello:
Vectores como representaciones de sitios web
En primer lugar, la patente propone partir de sitios dentro de una temática determinada. A cada uno de esos sitios, se le asigna una representación o “vector” y una puntuación de calidad.
Después, se clasifican los sitios en dos grupos, según estén por debajo de un primer umbral de puntuación de calidad, o por encima del primer umbral.
Para cada uno de estos grupos, se calcula una representación o vector medio, que es la combinación de todos sus vectores, o la tendencia central de ese grupo.
Una vez hecho esto, cuando se recibe un nuevo sitio web, se calcula su vector y si está más cerca del vector medio del primer grupo, se considerará a ese sitio como parte del primer grupo, si está más cerca del segundo se le considerará del segundo, y si está igual de lejos de ambas medias, se le considerará como de un tercer grupo.
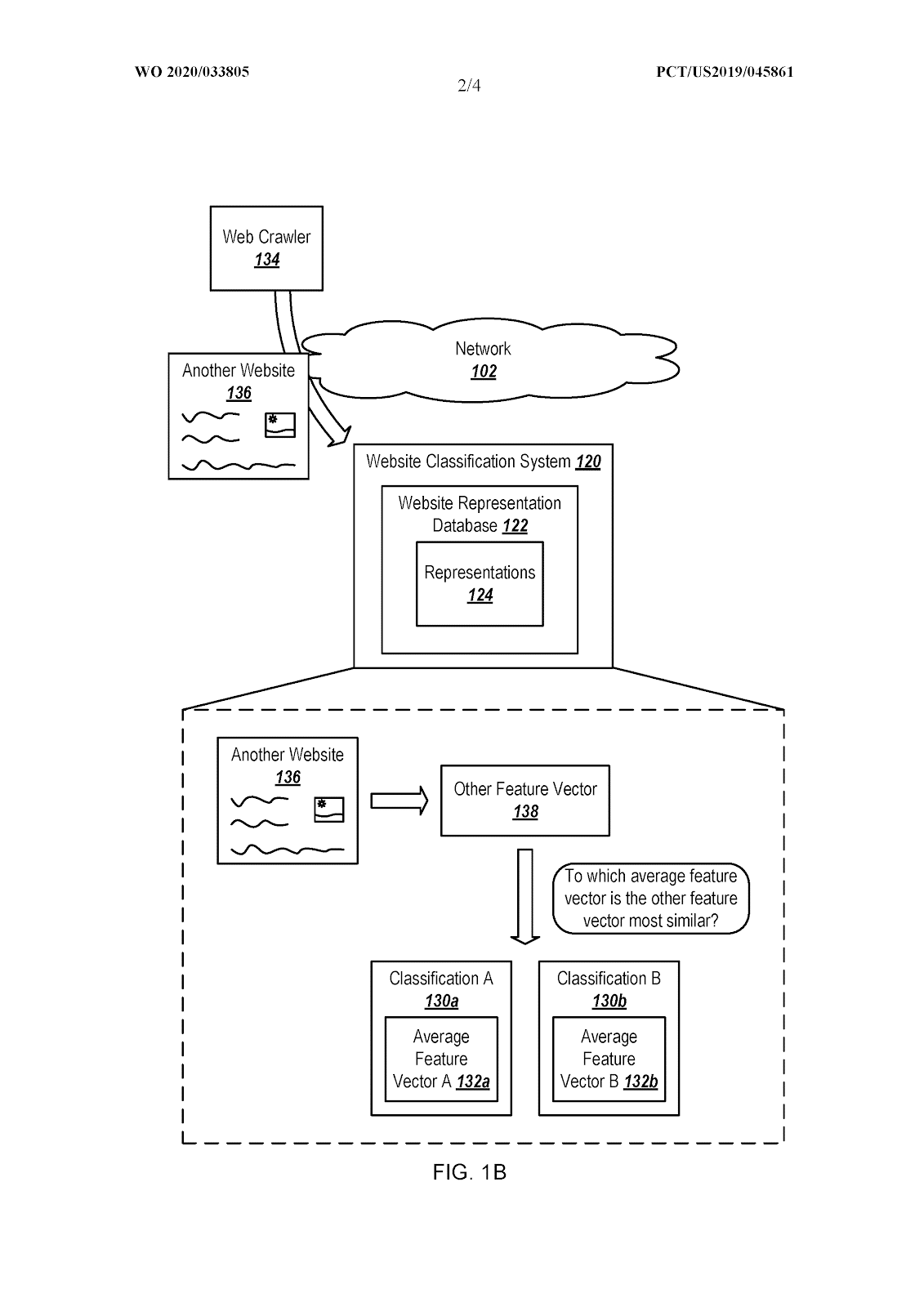
Así, es posible distribuir a todos los sitios webs de una determinada temática dentro de tres grandes grupos, que podrían corresponder a:
- Sitios cuyos autores no son expertos en la materia concreta
- Sitios de autores ligeramente expertos o “aprendices” de una materia
- Sitios de autores expertos en la materia
Uno de los ejemplos usados por la patente es el de webs con artículos escritos por personas sin conocimientos específicos de medicina, webs con artículos escritos por estudiantes de medicina y webs con artículos escritos por médicos.
Aunque es importante señalar que la patente usa también ejemplos de otras temáticas o áreas de conocimiento, como inteligencia artificial, educación y astronomía.
También es cierto que en la parte de la patente que describe cómo podría funcionar un sistema de clasificación de sitios web basado en redes neuronales, se menciona que la agrupación podría tener otros fines diferentes a determinar el grado de experiencia en la materia de sus autores, como por ejemplo determinar si la web corresponde a una organización sin ánimo de lucro o a una organización comercial.
Un método que funcionaría sólo para determinadas queries
Aunque esto ya es bastante, todavía queda miga. Tras esta exposición inicial, la patente entra en lo que se conoce como “posibles plasmaciones o implementaciones”, que no es otra cosa que Google tratando de cubrir todas las posibles formas de aplicar la teoría, pero sin llegar a a ser tan específicos que el sistema quede al descubierto.
La primera “posible implementación” es que el sistema empiece a funcionar sólo a partir del momento en el que se decide que una query o búsqueda introducida por el usuario pertenece a una temática determinada y requiere de una respuesta por parte de expertos en esa temática. Eso haría que Google buscase sólo entre los sitios previamente clasificados como expertos en esa temática, descartando el resto, aunque tengan contenidos relevantes para la búsqueda (query).
Podríamos decir que si para Google el tema de la búsqueda requiere un contenido experto, sólo sitios previamente catalogados como expertos en ese tema podrán ser devueltos como resultado. Los sitios catalogados por Google como no expertos en ese tema sencillamente no serían elegibles. Cuento más sobre esto en el apartado “Comparando la patente con casos reales”.
Ojo, la patente no especifica en ningún caso cómo serían rankeados los sitios expertos en la temática, escogidos como aptos para responder a la query. Por ello, lo más lógico es suponer que, una vez hecho el filtrado para obtener los sitios “aptos” por el método descrito, se aplicarían los métodos de ranking tradicionales, basados en puntuación de relevancia, autoridad, etc.
Se puede decir por tanto que esta patente no trata sobre métodos de ranking; de hecho sólo menciona el término “rank” dos veces y dentro de una descripción general de los procesos básicos de un buscador. Sí trata con métodos para clasificar sitios y para clasificar queries (muy importante, puesto que Google se encuentra millones de queries diferentes cada día). De hecho, la patente dedica un epígrafe a enumerar posibles ventajas del método propuesto, entre ellas reducir el consumo de recursos necesarios para guardar y extraer los resultados para una búsqueda. Todo esto son cuestiones estructurales, importantes para el funcionamiento de un buscador, pero que no tienen relación directa con el proceso de ranking.
Te recomiendo este post para leer más sobre los grupos de factores que Google usa en sus rankings, y cómo se combinan entre sí.
Uso de redes neuronales
Otra posible implementación muy importante, descrita además con bastante detalle en el ejemplo propuesto en la patente, es que Google haga todo esto mediante una red neuronal, previamente entrenada.
Si a esta red se le han suministrado suficientes ejemplos de sitios con artículos escritos por expertos en una temática, y suficientes ejemplos de sitios escritos por personas no expertas en ese mismo tema, y si se han definido una serie de “puntos” o características en los que fijarse para extraer y comparar vectores, con el tiempo esta red puede colocar sitios previamente no analizados en uno u otro grupo en automático. No hace falta que ninguna persona introduzca input manual alguno acerca de los nuevos sitios.
Esto no debe confundirse con que se usen las puntuaciones de los evaluadores manuales como material de entrenamiento para la red neuronal. En primer lugar, la patente no hace ninguna mención a evaluadores manuales por ningún lado, y en segundo lugar, Google ha negado explícitamente y varias veces que usen a los evaluadores para entrenar sus algoritmos (Fuente: Danny Sullivan en Twitter).
Sí usan el input de los evaluadores manuales para verificar si los cambios propuestos con un update al algoritmo que están a punto de lanzar, o acaban de lanzar, cumplen su objetivo.

Fuente 1: post en el blog oficial de Google Webmaster Center sobre core updates
Fuente 2: entrevista a Ben Gomes (Head of Search) en CNBC
Posibles señales para establecer el EAT de un sitio – ¿Qué hay de los enlaces?
¿Cuáles son estos “puntos” en los que se basa el sistema para efectuar su criba? Pues ahí está el quid de la cuestión y obviamente Google no puede permitirse ser específico, para que no haya posibilidad de manipular el sistema.
Pero la patente sí da una serie de ejemplos “abiertos” (muy abiertos), como el texto dentro de un sitio, las imágenes de ese sitio, los enlaces hacia ese sitio desde otros sitios, y una combinación de todos estos factores.
¿Esperabas algo más concreto? Seguramente nunca tendremos algo así.
Pero creo que sí tenemos un interesante hilo del que tirar. Google ha dicho muchas veces que la autoridad se mide por medio de muchas señales diferentes, una de las cuales es el PageRank de toda la vida.
Esta patente nos está diciendo que los enlaces se pueden usar para separar contenido experto del no experto. La lógica nos dice que una diferencia podría venir del origen de esos enlaces, ya que los sitios expertos y de calidad pueden enlazar hacia otros sitios expertos y de calidad, pero nunca o casi nunca enlazarán hacia sitios no expertos en su temática.
Esto podría hacerse partiendo de una serie de sitios identificados previamente como de calidad o expertos en su tema. ¿Te suena? Es el método de páginas semilla, del que hablé en este post sobre una patente que actualiza PageRank.
Y es suponer más aún, pero la red neuronal también se podría usar para identificar una serie de características que reúnen esos sitios expertos que suelen enlazar hacia otros sitios expertos, y a partir de ahí escalar el sistema.
Google no necesitaría etiquetar las páginas semilla, o que comparten características con otras páginas semilla, una a una, sino que lo haría la red neuronal, y a partir de ahí fluiría la autoridad dentro de una temática concreta.
Por último, respecto a si Google está evaluando el sitio en su totalidad, o sólo algunas páginas, es algo que queda también abierto, ya que específicamente hay una mención a que los vectores podrían crearse atendiendo sólo a un conjunto de páginas representativas del sitio.
Comparando la patente con algunos casos reales
Volvamos ahora a Medic. Este core update fue denominado así no por Google, sino por la comunidad. Creo que fue Barry Schwartz el primero en usar este nombre en los días siguientes al update (que empezó a notarse el día 1 de agosto de 2018), porque inicialmente había un gran número de sitios de salud entre los más visiblemente afectados.
Con el tiempo se vio que como todos los updates al núcleo del algoritmo, en realidad había tenido efecto sobre sitios de temáticas muy variadas, por no decir que de todas las temáticas.
Pero sí es cierto que entre los sitios que tocaban temas como finanzas o salud se podían ver los mayores estragos, con pérdidas del 60% y el 70% del tráfico orgánico en el curso de unos pocos días. Esto lo pude comprobar en su momento en varios sitios, a través de Analytics y Search Console. Pego aquí un ejemplo real:
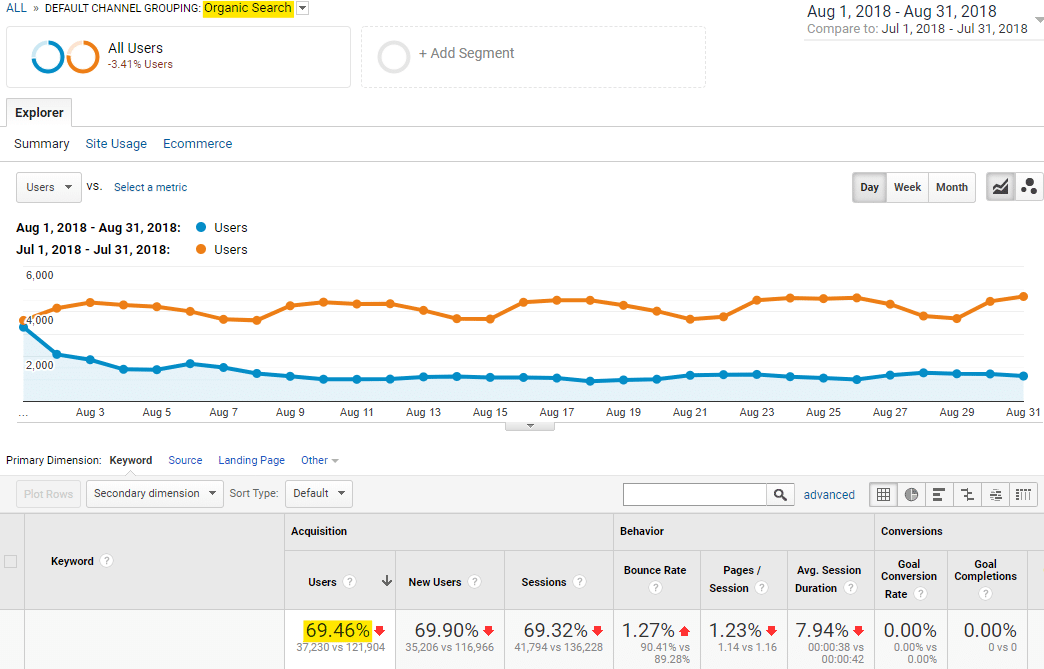
Lo que también pude observar y he venido observando desde entonces es que no todas las búsquedas se veían afectadas por igual. Es decir, a pesar de que algunos sitios desaparecían totalmente de los rankings en un buen porcentaje de sus queries, perdiendo por tanto el tráfico orgánico que les llegaba por esas queries, al mismo tiempo se mantenían o en ocasiones incluso subían en otras queries.
¿Curioso, verdad? No estábamos por tanto ante un algoritmo que penalizase (o evaluase) al sitio en su conjunto, sino dependiendo de la query.
Un ejemplo, sacado del mismo sitio cuyo Analytics he mostrado arriba.
Se trata de un blog con información general sobre salud y educación de niños y bebés. Su autora no es médico o estudiante de medicina, ni tampoco enfermera. Sí es experta en nutrición, y además habla del tema desde su experiencia personal, ya que ella misma es madre.
El sitio obviamente perdió miles de queries orgánicas con el Medic Update, entre las cuales se encontraban términos que podemos considerar dentro del ámbito de la medicina, aunque sea de atención primaria, como por ejemplo:
“Placas en la garganta” y términos derivados, como “placas en la garganta niños”, etc.
Estos términos venían obteniendo buenas posiciones orgánicas hasta julio de 2018, como podemos ver usando el histórico de SEMrush:
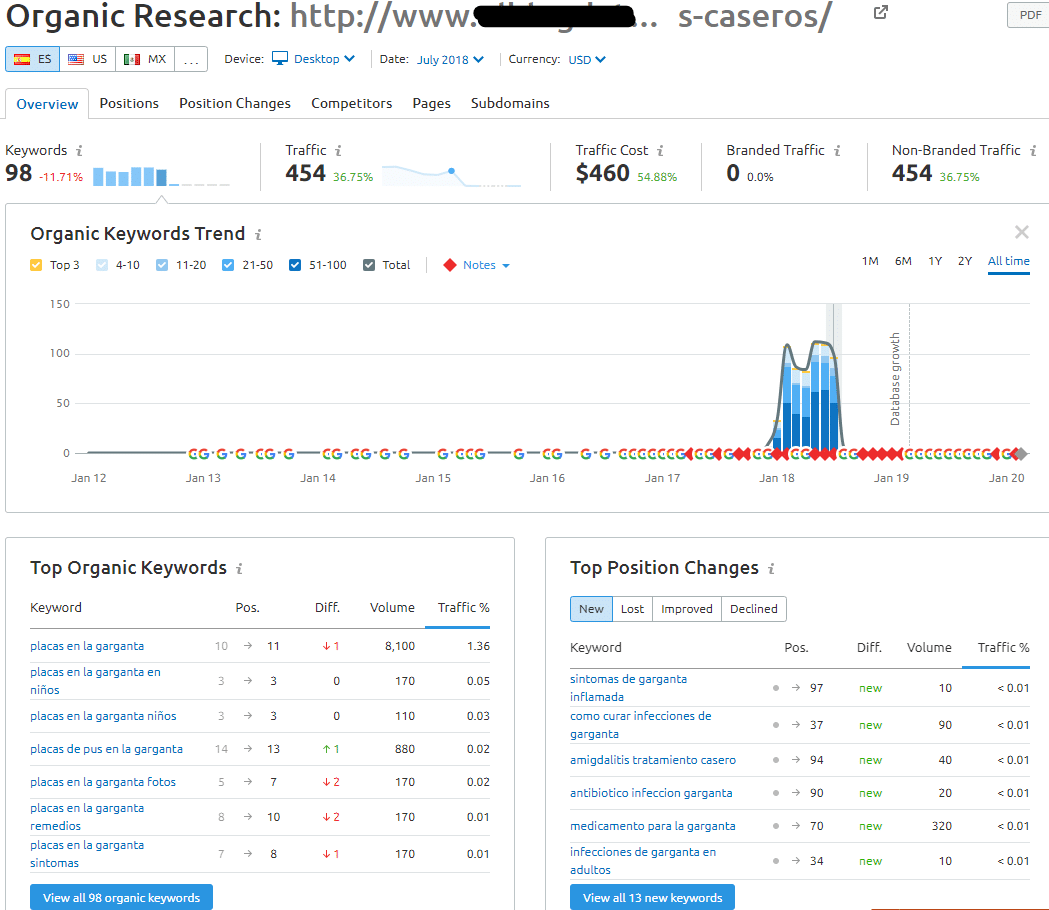
Fuente: SEMrush
A día de hoy, estos son las únicas palabras clave con mención al término “placas” para las que este sitio sigue posicionando orgánicamente en España. Todas ellas longtail y siempre en posiciones muy alejadas. El resto han desaparecido.

Fuente: SEMrush
Por poner algo de contexto, el tráfico orgánico de este sitio vivió una relativa recuperación en el update de marzo de 2019 – pero las keywords importantes del cluster “placas en la garganta” en ningún momento se han recuperado.
Por el contrario, el sitio ha mantenido rankings altos en miles de queries relacionadas con temas no médicos, como por ejemplo trámites administrativos relacionados con ayudas a madres trabajadoras y familias numerosas, consejos para elegir silla de bebé, manualidades para hacer con niños, y por último recetas y temas relacionados con la nutrición.
Temas todos ellos para los que no son necesarios conocimientos expertos en medicina.
De la misma manera, por poner otro ejemplo más, el blog de un ecommerce de productos de parafarmacia perdió las keywords que tocaban temas relacionados con condiciones médicas, pero mantuvo en primera posición palabras clave informacionales que no pertenecen propiamente al ámbito médico, como por ejemplo “te verde para quedar embarazada”.
Son sólo un para de ejemplos, pero he visto suficientes casos en la misma línea como para saber que no son un par de casos aislados, y que Medic y otros updates posteriores han discriminado por query, en lugar de condenar al abismo a todo un sitio.
Obviamente, puede darse el caso de un sitio que sólo hable de temas médicos, y que no se considerado por Google como parte del grupo de sitios expertos en la temática. En un caso así, un sitio podría perder todos sus rankings, salvo quizá los términos de marca, si es que tenía algún tráfico de marca previamente al update.
Pero eso no quiere decir que Google esté actuando a nivel de sitio. Lo hace a nivel de query, y se da la coincidencia de que ese sitio en concreto sólo posicionaba para el tipo de queries que Google está filtrando. Sería la excepción, y no la regla.
Conclusión
Quizá lo explicado hasta el momento no aporte nada radicalmente nuevo a los que llevan ya muchos meses trabajando con bajadas y subidas de tráfico orgánico en sitios de temáticas YMYL.
Lo novedoso es que ahora tenemos un documento creado dentro de Google que ofrece una explicación teórica, si bien no demasiado específica, a lo que algunos intuíamos, pero no teníamos en qué apoyar de manera teórica, más allá de las declaraciones oficiales sobre updates de Google, en general muy ambiguas.
Aparte de la evidencia puntual que he mostrado en los ejemplos de más arriba, la idea de que Google trate con una vara de medir más estricta los temas englobados dentro de YMYL tiene lógica (porque se arriesga a una demanda si rankea en los primeros lugares información falsa o que ponga en peligro la salud de sus usuarios) y además esto está reconocido explícitamente en la Guía para evaluadores manuales.
No sólo ahí, sino en un white paper publicado por Google en febrero de 2019 titulado «How Google Fights Disinformation«. En la pagina 13 mencionan explícitamente que tratan de forma especial las temáticas YMYL, en las cuales lus usuarios esperan que Google ponga un cuidado especial:

En definitiva, tanto si esta es la patente detrás del intento de medir EAT en esos temas sensibles como si no, una conclusión que podemos sacar de la misma, y de las comunicaciones menos ambiguas de Google alrededor de este tema (especialmente este post) es que Google ha mejorado a la hora de analizar qué webs ofrecen contenidos expertos para ciertos temas sensibles.
Pretender rankear bien para estos temas sin ofrecer un contenido a la altura de unos mínimos estándares y sin contar con el tipo de señales que se suelen encontrar en este tipo de sitios web expertos (por ejemplo, enlaces desde organismos oficiales o centros de investigación y otras fuentes académicas) puede haber funcionado hasta hoy, pero casi seguro dejará de funcionar pronto, si no lo ha hecho ya.
Según desde donde lo mires, esto pueden ser malas o buenas noticias. Yo prefiero pensar que son buenas, y en el futuro, para sitios que toquen este tipo de temas, en USEO seguiremos trabajando como lo hemos hecho hasta ahora, pero con más confianza.
Tus rankings para ciertas palabras clave peligran si no eres un experto o si no puedes demostrar que lo eres, y si es el caso, quizá sea mejor que te centres en palabras clave que no requieran de esa consideración de experto, como en el blog infantil que he puesto de ejemplo.
De igual manera que en el SEO de toda la vida se han priorizado keywords según veíamos cómo de fuerte estaba la competencia para cada keyword (estimando su autoridad por número y calidad de enlaces), ahora deberíamos centrarnos sólo en aquellos temas en los que nuestro sitio tenga posibilidades reales de ser considerado un sitio experto.
Si es estrictamente necesario para los objetivos del negocio rankear en ciertos temas sensibles, pero parece que para Google no cumplimos con lo necesario para ser considerado experto (observable por la ausencia de rankings en esos temas) habrá que trabajar a medio y largo plazo para poder cumplir los requisitos y poder entrar en el grupo “experto” de sitios.
Y tú, ¿qué opinas? Te espero en los comentarios.

Muchas gracias Juan
Llevo dándole vueltas al post de Bill Slawski desde que lo leí hace unos días… ¡Qué bien lo explicas!
Me «cuadra bien» con lo que llevo viendo (e intuyendo) desde agosto 2018 en el sector salud.
Google es muy capaz de alinear en las principales querys sanitarias la RELEVANCIA (factores SEO convencionales) con la autoridad / crédito de la fuente como medio para garantizar que la info sea CORRECTA.
Un saludo
Gracias a ti, Eduardo. Sabía que te interesaría el tema y que lo habrías estudiado ya por tu parte.
Sí, a mí también me cuadra con cosas que he visto… Aunque debemos tratar de huir del «sesgo de confirmación», es decir, no usar la patente para reforzar lo que ya pensábamos antes, si no hay más evidencia. Aunque ya sabes que desde Google nunca darán información más específica que esta.
Me gustaría ver si ha habido casos desde agosto de 2018 que estén en contradicción con la patente (y que no se puedan explicar por otros algoritmos ya conocidos).
Saludos y gracias por comentar, Eduardo!
Yo personalmente le veo una alta relación entre esta patente y los movimientos que ha habido desde aquel fatídico verano….
De hecho todos los altibajos que hubo en su momento, entiendo que era la aplicación por fases de dichos cambios.
Los que primero bajaron y después subieron, no fue porque lo hicieran bien sino porque otros habían bajado más aún e indirectamente habíamos subido otros. Fueron meses de locura.
Resulta comprensible, que google haya barrido «los nichos de salud», yo tenía un par de páginas que han sido vapuleadas literalmente.
Los nicheros tienen las horas contadas, pero no por nicheros, sino por no ser expertos en los temas que tocan. Al final google quiere gente/empresas/marcas que de verdad sea experta en lo que habla. Ya que el usuario entrará, leerá y juzgará.
Lo peor para google tras una búsqueda, es poner bing.com/yandex/duckdukgo… etc en el navegador.
Gracias Juan, como siempre es un placer leerte. Esto si hubiera sido explicado en reportin.pro, seguramente a más de uno le estalla la cabeza. 😀
Un saludo.
Muchas gracias por el comentario, Rafa! Jeje, sí, no me acaba de cuadrar el tema para un episodio de Reportin. Quizá uno más accesible sobre qué es el EAT y una breve mención a esta patente. Saludos!
Muy buen artículo! estoy muy interesado en todo el tema E-A-T y llevo meses leyendo todo lo que pillo del tema y la patente realmente cuadra totalmente. No nos aporta nada ‘accionable’ en sí, pero como dices confirma cosas.
Super bien explicado todo Juan, el readability por las nubes 🙂
Jaja, pensaba que te ibas a esperar al tren para leerlo. No, en serio, muchas gracias por tu comentario, Carlos! Me alegra ver que otros compañeros del gremio pensáis de manera parecida a mí. 🙂
Gran análisis Juan !! Desde luego deja ver ‘señales’ de lo que podríamos intuir después de todos los movimientos desde ese verano. Esta claro que la ‘calidad’ de los contenidos y fiabilidad se asentó como señal única para que nuestras webs estén ahí arriba. Lógico por otro lado… seguiremos ‘estudiando’ . Un abrazo
Gracias, Fernando! Sí, en esto del SEO siempre hay que seguir estudiando y trabajando. Un abrazo.
Hola Juan! Genial como siempre tus posts! Muchas gracias por compartir.
Sería bueno ver cómo esos sitios que quizás al día de hoy no sean considerados como expertos, y a su vez están bien posicionados en temáticas sensibles, podrán ingeniárselas para trabajar este aspecto de lograr tener «autoridad y fiabilidad» antes los ojos de Google. Qué piensas?
Saludos!
El markup de author y publisher ayudan a identificar expertise no?
Hola Jose, la patente no hace ninguna mención al rel=author, y la postura oficial de Google respecto al uso de rel=author es que ya no está «supported» en Búsqueda. https://support.google.com/webmasters/answer/6083347?hl=en Cuando sí se usaba, era un marcado, como el markup de producto o de evento, no un factor de ranking, aunque sí daba muy buen CTR en las serps (gracias al uso de la foto de autor, que destacaba mucho sobre resultados que no lo tenían).
El rel publisher también ha quedado obsoleto desde la muerte de Google+, y Google prefiere que se use marcado de schema.org para especificar la organización que produce el contenido. Pero tampoco creo que el mero hecho de etiquetar un contenido como producido por cierta organización sea un factor de ranking, o tenga necesariamente que ver con la manera en la que Google valora el EAT.
Gracias por tu artículo Juan.
Yo siempre he intuido que junto con el PageRank, otra de las señales para rankear es un factor de WebSpam, que bien podría afinarse con esta patente.
La idea sería que, una vez asociado a una URL dicho valor de webspam, y calculado el valor medio (para una intención de búsqueda), todas las URL que estén por debajo, son descartadas y no aparecerán en el SERP aunque tengan el resto de señales con un valor alto.
Como colofón, para el SEO actual, se tendría que primar estar por debajo de la media de webspam, antes que potenciar otras estrategias, que serían anuladas.
Hola, Feliciano, muchas gracias por comentar. Lo que comentas es una posibilidad, y no niego que en algún momento haya sido así, pero si en el Medic y en algún core update posterior han hecho esto, ha sido con un filtro sobre el tipo de query, es decir, para algunas sí (las de temáticas sensibles) y para otras no, o al menos con umbrales más bajos. Porque, como digo en el artículo, una de las cosas que se apreciaban en sitios afectados es que en ciertas queries se desaparecía radical, y en otras las posiciones se mantenían como si no pasara nada. Saludos, Feliciano!