

El 31 de marzo de 2023 Twitter hizo público el código de su algoritmo de recomendación, es decir, el sistema que decide qué tuits mostrar en la pestaña For You de cada usuario, y en qué orden se muestran esos tuits.
Podemos acceder a este código en este repositorio de GitHub. Para los que no tengan ganas de bucear entre esta multitud de archivos, escritos en Java, Python, Scala, Rust y otros lenguajes, hay un interesantísimo post en el blog de ingeniería de Twitter, explicando a grandes rasgos cómo funciona.
He seguido esa explicación, ampliando un poco por mi cuenta hasta donde me ha sido posible, y he preparado este resumen en español, creo que el primero publicado hasta la fecha sobre cómo funciona el algoritmo de recomendación de Twitter.
Sin más preámbulos, vamos a ello:
Seleccionar tuits candidatos
No todos los tuits son considerados como candidatos para aparecer en la pestaña For You de los usuarios. Algunos son descartados de entrada. Este proceso, previo a la ordenación o rankings, consta de dos fases:
Fase de recopilación de datos
Para que el sistema tenga criterios para seleccionar y ordenar tuits, hay que alimentarlo de datos. Los datos con los que va a trabajar salen de 3 fuentes:
• El Follow Graph (quién sigue a quién)
• Las métricas de interacción de los tuits
• Otros datos de usuarios (como por ejemplo a quién has bloqueado / muteado, qué contenidos te interesan, etc).

Fase de aplicación de cálculos
Sobre esta base de datos, se aplican una serie de cálculos o features, de los que, ahora sí, saldrán los «tuits candidatos».
Uno de estos cálculos es el RealGraph, un modelo que calcula la probabilidad de que te interese lo publicado por cierto usuario (incluso si nunca antes habéis interactuado).

Otro es el TweepCred, que es en realidad un PageRank, algoritmo ideado por Google para rankear páginas web, pero que en la práctica es aplicable para encontrar los elementos más influyentes o con más autoridad de cualquier grafo o red (en este caso, la red de usuarios de Twitter).
Según esto, eres más influyente, cuanto más influyentes son los usuarios que interactuan contigo.

Hechos los cálculos de esta fase, se seleccionan como candidatos unos 1500 tuits, de los cuales un 50% salen de las cuentas que sigues, y un 50% de cuentas a las que no (aproximadamente, en realidad esta proporción varía para cada usuario).

Tuits en tu red y fuera de tu red
Para decidir qué tuits serán candidatos de fuera de tu red usan dos métodos: el Social Graph y Embedding Spaces.
Social Graph es una forma de buscar contenido afín a tus gustos: tuits con los que han interactuado usuarios que sigues y tuits con los que han interactuado usuarios con gustos similares a los tuyos.

Los Embedding Spaces son más complejos, pero también buscan encontrar tuits y usuarios afines a tus intereses.
Embedding es una técnica para transformar en números cadenas de texto (por ejemplo tuits). Hecho esto, se puede determinar el grado de similaridad entre dos tuits, o entre dos conjuntos de tuits.

Hay varios embedding spaces. Uno de los más importantes para el algoritmo es SimClusters, un sistema que crea «comunidades invisibles» dentro de Twitter, agrupadas en torno a una serie de usuarios influyentes.
Hay 145.000 comunidades generadas por SinClusters, y se actualizan cada 3 semanas. Tanto los usuarios como los tuits pueden pertenecer a más de una comunidad.

Las comunidades pueden tener entre unos pocos miles de usuarios y varios cientos de millones (es el caso de las comunidades más masivas, como pop, noticias, fútbol).
Cuanto más le gusta un tuit a los usuarios de una comunidad, más asociado con la comunidad estará ese tuit.

Fase de ranking
Bien. Tenemos 1500 tuits candidatos y llega el momento de ordenarlos en tu pestaña For You.
Heavy Ranker
De esto se encarga una red neuronal de 48 millones de parámetros llamada Heavy Ranker. Esta red neuronal es entrenada continuamente con datos de interacción de tuits, para obtener el mejor resultado de interacción posible.

Es decir, el Heavy Ranker tiene la misión de colocar más arriba los tuits que, según los datos observados anteriormente, tienen más posibilidades de generar interacciones.
Esto es un funcionamiento habitual en los algoritmos de recomendación de cualquier red (Facebook, YouTube, Discover).
Ahora, como bien me señala Natzir Turrado, el resultado al que llega la red neuronal podría estar guiada por unos pesos específicos para ciertos parámetros, presentes en varias partes del código compartido recientemente por Twitter. Esta sería la forma que tienen los ingenieros de Twitter de “influir” de manera general en los rankings devueltos por la red neuronal.
Nota: no doy por seguro que estos pesos estén en uso ahora mismo, o que lo estén en todo momento, primero porque el post de Twitter no los menciona (aunque esto puede ser para ahorrarse complejidad al describir el proceso), y segundo porque el hecho de que algo esté incluído en el repositorio de código no quiere decir que de verdad se aplique, o se aplique siempre. Podría ser tanto un mecanismo de control que los ingenieros de Twitter apliquen puntualmente (por ejemplo, en momentos donde es vital para Twitter filtrar desinformación, como por ejemplo una elección presidencial en EEUU), como un sistema general aplicado siempre para guiar los outputs de Heavy Ranker.
Entre los parámetros con un peso más alto (la red está programada para darle más importancia) tenemos:
- El número de FAVs de un tuit
- El número de RTs
- Si el tuit es de alguien a quien sigues
- Si el tuit es de alguien que está en tu círculo «de confianza» (esto podrían ser usuarios con los que has intercambiado DMs, o te tuiteas a menudo)
Otros factores con un peso menor:
- Si el tuit trata sobre un tema de tendencia
- Que el tuit incluya imagen o vídeo

Fase de filtrado
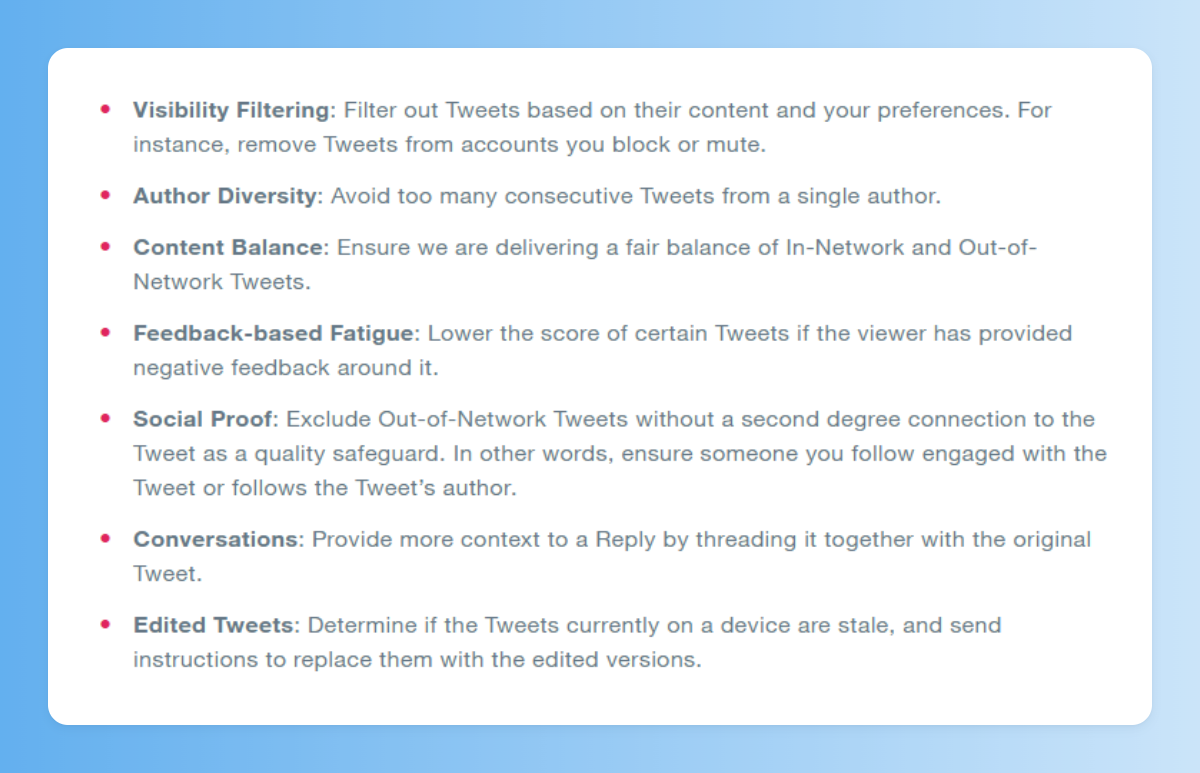
Tras el rankeado, queda filtrar/modificar de acuerdo a criterios especiales, como por ejemplo:
• Extraer de tu feed temas que has expresado que no te interesan, y tuits de usuarios a los que has bloqueado o muteado
• Evitar que se cuelen demasiados tuits del mismo autor en el feed de un usuario
• Excluir tuits en los que no hay una relación de segundo grado contigo (alguien a quien sigues debe seguir al autor del tuit, o haber interactuado con el tuit)
• Añadir el tuit original cuando se trata de una respuesta o conversación
Balancear el número y orden de tuit extraídos de personas a las que sigues y de fuera de tu red. Imagina que en el orden determinado por Heavy Ranker, los 100 primeros tuits fueran todos de personas a las que no sigues. Esto probablemente produciría quejas, así que Twitter lo equilibra.

Mezclar con otros contenidos y servir los resultados
Ya sólo queda intercalar otros tipos de contenido, como anuncios o recomendaciones para seguir a otros usuarios, y la cadena de tuits está lista para servirse.
Esto sucede unos 5000 millones de veces al día, y todo el proceso se ejecuta en un segundo y medio. 🙀

Aquí tienes un esquema del proceso completo:

Conclusiones que se pueden sacar para tener más alcance en Twitter
Esto por supuesto es sólo una visión general, hay aún muchos detalles que pueden tener impacto en el resultado final, y seguro que en los próximos días aparecerán muchos descubrimientos y conclusiones interesantes.
Aunque aún hay mucho que analizar, estos son algunos principios generales que creo que pueden ayudar a tener más interacción y por tanto más alcance en Twitter:
- Encontrar tu “espacio” es importante, y también participar en ese espacio con frecuencia (recordemos que los espacios o comunidades se reordenan cada 3 semanas). Si tuiteas de forma inconsistente, cada vez sobre temas diferentes, y de repente desapareces dos semanas o más de Twitter, el sistema no sabrá dónde ubicarte. Por el contrario, una de las mejores cosas que puede pasarte es que te ubique en el centro de una de sus comunidades.
- Tratar de imitar tuits que han funcionado bien, en forma y contenido, parece en general buena idea, pero cuidado con pasarse, ya que entonces los usuarios podrían rechazarte por “copiota” (bloqueándote o muteándote), y acabarías logrando el resultado contrario, cada vez menor alcance e interacción.
- Lo mismo pasa con pedir directamente interacción. De siempre se sabe que si incluyes en el tuit, “por favor FAV o RT”, ese tuit suele rendir mejor, pero si lo haces con demasiada frecuencia te acabarán ignorando.
- Crecer en seguidores, siempre que sean seguidores a su vez activos en la red, tiene beneficios claros.
- Por otro lado, si te bloquean o mutean a menudo, eso hace que tu alcance potencial vaya disminuyendo, por lo que es mejor tratar de no molestar o despertar animadversiones, si quieres tener el mayor alcance posible. Aunque parezca que esto abriría la puerta a «ataques negativos de reputación» si muchas cuentas se ponen de acuerdo para bloquearte, en la práctica tiene que haber contrapesos para evitar esto, y de hecho si no te bloquean usuarios reales y que a su vez tengan alcance e influencia, el impacto negativo de esto probablemente sea muy bajo.
- Cuanto mejor funciona un tuit, más probabilidades de aparecer en la pestaña For You. Por tanto, no te deesperes si notas que en los primeros minutos un tuit no logra alcance ni interacción, ya que al poco de publicra un tuit, le fala uno de los factores que probablemente tenga más peso, que es la propia interacción de los demás usuarios.
En fin, hasta aquí el resumen.
¿Qué te ha parecido? ¿Crees que podría ser manipulable (más allá de «fusilar» tuits que han tenido buen engagement, o de solicitar directamente interacción con el tuit)?
