

The Custom JavaScript function is one of the main novelties of the latest version of Screaming Frog (20), released in May 2024. With it, we can execute JS to extract data and perform actions on the URLs that the bot is crawling, such as generating text or meta tags for each URL with the OpenAI API, or scrolling within the page.
In this tutorial, I’m going to explain how to extract the main content of each page. In other words, how to extract the important text or main content of a URL, excluding menus, dates, sidebars, footer, ads, etc.
Readability.js is a JavaScript library used in Firefox’s Reader View, a feature of this browser to read without distractions, similar to the one Chrome has.
Readability can extract either the entire HTML of a URL, or just its text content, and it can also offer you data such as a brief summary of the content (excerpt), the author, the estimated reading time, or the readability level of the text.
Since I’m looking for agile methods to extract embeddings from a site’s URLs, but I don’t want those embeddings to be «contaminated» by parts of the page that may be irrelevant, such as menus and especially sidebars and footers, this library seemed very interesting to me for creating my first Custom JS, which has turned out to be super simple.
Isn’t this something that has always been possible with Screaming Frog? Well, as far as I know, there has never been a default field to extract the main content of any page, since this can vary a lot depending on each website, and that’s why it’s necessary to resort to a library that already deals with that problem.
If you wanted to do it for a specific website, you’ve always been able to do it through the Custom Extraction function, which allowed you to tell the crawler exactly where the content you were interested in was.
But of course, that was for a single website, and it might not work for the next one. With Readibility.js, what we’re going to have is a method that will work, without touching anything, for a good proportion of websites.
Let’s see how to do it, and you’ll be able to use this same Custom JavaScript snippet, or create your own.
How to create your own Custom JS for Screaming Frog
In Screaming Frog, go to Configuration > Custom > Custom JavaScript
Click create and a row with several fields to fill out will appear.
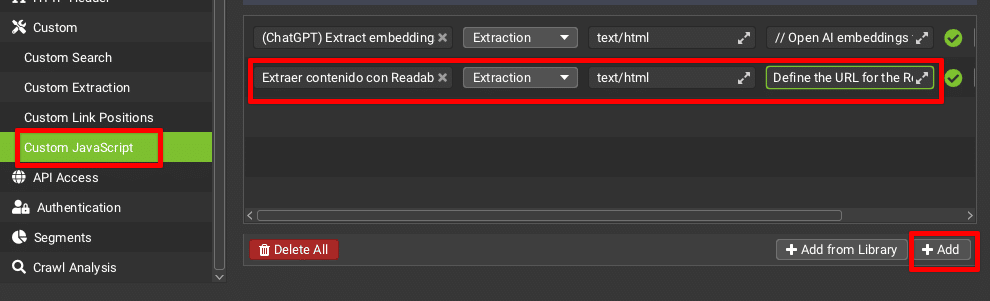
In the first field, put the name of your Custom JS.
As the Screaming Frog documentation explains, there are two types of Custom JS: extraction and action. The one we need in this case is extraction, since we’re going to extract data from the URLs we crawl, and that’s what we should choose in the dropdown (second field).
text/html: this field specifies what type of URLs your Custom JS will run on. Leave it like this if you only want to run it on HTML pages.
Finally, in the next field, we’re going to put the JS code that Screaming Frog should execute. Click on the little arrows to open the snippet editor.
In this case, we need to tell it where our library is, then we need to ask it to analyze the current URL and we need to give it an action to execute (extract the «text content»). The final code will look like this:
// Define the URL for the Readability.js library
const readabilityJsUrl = "https://cdnjs.cloudflare.com/ajax/libs/readability/0.4.4/Readability.js";
// Load the Readability.js library
return seoSpider.loadScript(readabilityJsUrl)
.then(() => {
try {
// Create a clone of the document to avoid modifications to the original DOM
const documentClone = document.cloneNode(true);
// Initialize Readability with the cloned document
const reader = new Readability(documentClone);
// Parse the document to extract the article
const article = reader.parse();
// Check if article parsing was successful
if (article) {
// Return the text content of the article
return seoSpider.data(article.textContent);
} else {
// Return an error if parsing was unsuccessful
return seoSpider.error("Failed to parse article content");
}
} catch (error) {
// Return any errors encountered during the parsing process
return seoSpider.error(`Error during parsing: ${error.message}`);
}
})
.catch(error => {
// Return an error if loading the Readability.js library fails
return seoSpider.error(`Failed to load Readability.js: ${error.message}`);
});
How to test that your Custom JS works
In addition to testing it by crawling (make sure you do it in JS rendering mode) and checking that it appears in the Custom JavaScript tab (and the column corresponding to the Custom JS we just created), we have a tool to test our snippet of code without needing to launch a crawl.
Open the JavaScript snippet editor by clicking on the little arrows in the field where you put your code, or on the button just to the right, which says «JS».
In the left box, at the bottom, you can put a test URL. Click Test and it will execute your Custom JS on that URL. If everything is correct, it will extract the content of the page and you will see it appear on the screen.

And we have created our first custom JavaScript for Screaming Frog.
How to save and share your Custom JavaScript
Since you’re going to use the snippet you created in more than one crawl, now you need to save it.
For this, we first have the Custom JavaScript Library. From the editor, click the «Add snippet to user library» button (just below the left box, where your code is displayed). Give it a name and it will be saved in your library.
To access the library, you can do so from Configuration > Custom > Custom JavaScript. There you have a button called Add to library, click on it and you will access all the saved JS snippets, both default (System tab) and those saved by you (User tab).
Want to share your Custom JS snippet with a colleague? Select the one you want and right-click. In the dropdown menu, choose «Export» and it will download in JSON format.
This JSON file can be loaded by anyone who has Screaming Frog from their own library. Under the User tab, there are two icons, one for importing and one for exporting. Click import and you’ll be able to upload any Custom JS that has been passed to you.
What do you think? Will you try creating your own code snippets? What ideas do you have for taking advantage of this great new Screaming Frog feature? Leave me a comment so we can all get inspired.
PS: If the idea of generating code in JS puts you off, know that I myself have minimal experience with JS, beyond creating the occasional super basic bookmarklet. But I generated and validated this code in less than a minute, feeding ChatGPT the Screaming Frog documentation for working with Custom JavaScript and the Readability.js documentation – easy, fast and suitable for anyone. 😉
