

I’ve found Google’s patent behind Google’s SGE, their experimental search engine with AI generated results.
The patent, «Generative summaries for search results» was filed on March 20th, a few weeks before the first announcement and beta release of SGE.
In this post I will explain how a system like Google SGE works, according to the patent.
First: there are currently no other patents assigned to Google mentioning generative AI techniques and search.
There might be other patents on the same topic still pending, but I believe this document is highly relevant to Google SGE as it works right now.
The patent, which describes how to «selectively use a large language model (LLM) to generate a natural language summary in response to a user query», matches what we see and know about SGE today.

Key Steps
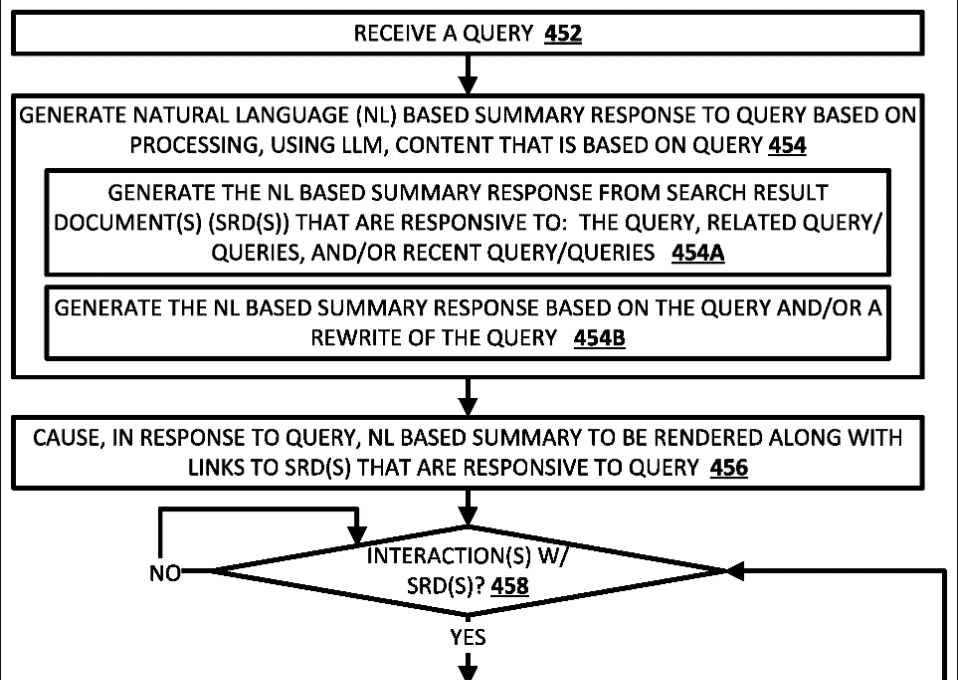
These are the key steps described by the patent:
1. Receiving a query associated with a client device. The query can be explicitly entered by a user or automatically generated based on context.
2. Selecting a set of search result documents (SRDs) that are responsive to the query and related or recent queries.
3. Generating corresponding content snippets from each SRD. This can include text, images, video content, etc.
Content can be selected based on correlation with the queries.
4. Processing the SRD content snippets using an LLM to generate LLM output. An optional summarization prompt can also be included.
5. Generating a natural language summary using the LLM output. This leverages robustness of the LLM while constraining it to the SRD content.
6. Rendering the summary at the client device, along with optional search results, confidence annotations, links to verifying SRDs, etc.
One or More LLMs and AI Models
A few elements stand out. For example, the fact that more than one generative models are available for creating the summary.
This checks out with something stated in the document «An Overview of SGE«, made public by Google around SGE’s launch, although we didn’t have any more details.
The patent now provides plenty of detail around how and why several models are available and can be used:
1. Several candidate generative models are available, including multiple LLMs and optionally other models like text-to-image models.
2. Based on analyzing the query and search results, one, none or several of the candidate models are selected to use for response generation.
3. The selection can be based on:
• Processing the query with a classifier to predict best model(s)
• Detecting certain terms in the query to indicate suitable model(s)
• Considering search result types/content to determine appropriate model(s)
4. Tradeoffs are made between accuracy and resource utilization when selecting models. The system may prefer smaller LLMs, unless a larger one is better for the query.
5. If multiple LLMs are selected, multiple responses can be rendered using the different LLMs.
So by dynamically selecting from multiple candidate generative models, the invention aims to optimize accuracy and efficiency by choosing the most suited model(s) for any given query.
Verifying Information with Links to Sources
The patent also provide some details on how the links to sources work:
In some implementations, when the natural language (NL) summary is rendered, selectable links can be included that link to search result documents (SRDs) that verify portions of the summary.
For example:
1. «A portion, of a visually rendered NL summary, that is supported by a first SRD can be selectable (and optionally underlined, highlighted, and/or otherwise annotated).
A selection of the portion can result in navigating to a link corresponding to the first SRD.»
2. The linkified portions help users quickly see which parts of the summary are verifiable and access the verifying content, and also «quickly ascertain supporting and/or additional information relating to the portion.»
3. The links can be general links to the SRDs or specific anchor links to the portions that provide the verification.
4. The linkified portions can be determined based on comparing the summary content to SRD content using encoder models to identify verified portions.

Confidence Scores and Annotations
Another very interesting part of the patent deals with confidence annotations.
I believe we haven’t seen those in SGE yet (Glenn Gabe or Lily Ray may know more about it), but Google launched a similar feature for Bard last September, the «Double-check response» button.
Here’s how confidence works, according to the patent:
1. Confidence measures can be generated for portions of the summary or for the summary as a whole.
The confidence measures are then used to determine which confidence annotation from a set of candidates should be applied.
2. The confidence measures can be based on:
• LLM confidence reflected in the LLM output
• Confidence in the search result documents (SRDs) that verify portions of the summary
3. A textual «high confidence», «medium confidence», or «low confidence» annotation can be annotated for the NL based summary as a whole.
Each of the portions of the NL based summary can be annotated with a corresponding color that reflects a degree of confidence in that portion.

I believe this is exactly what Bard is doing right now, with green for «high confidence», no highlighting color for «medium confidence», and orange for «low confidence».

How I Found Out About the Patent
Now, I’ll explain how I found out about this patent, and another interesting thing:
What Google SGE and Featured Snippets have in common… 🤓⤵
I was reading some documents made public during the US vs Google antitrust case. There, an email by John Gianandrea (former Senior VP at Google) mentioned an interesting contribution by an engineer named Steven Baker.
Intrigued, I looked for Baker in Linkedin…
According to his own career summary, he worked in SGE at Google between Nov 2022 and Sep 2023. He is now a Google Fellow, the highest rung on the ladder for Google engineers, which they reach thanks to «consistently outstanding accomplishments».

10 years before at Google, he had been in charge of «Answering All the World’s Questions (algorithmically)», a project internally called WebAnswers (what we SEOs know as Featured Snippets).
Steven worked together with Srinivasan Venkatachary in WebAnswers.
Their careers afterwards were very similar: they both went to Apple, where they worked in Search and Siri, and came back to Google at the end of 2022 to work in SGE.

So… how did I find the patent? I decided to look for patents by any of these two engineers and there it was.
So there you go, at least two engineers working in SGE had been instrumental around 10 years ago in developing the Featured Snippets (WebAnswers) system for Google.
I believe that’s why some like Marie Haynes have noted similarities between these two kinds of results.
If you enjoyed the post, sharing and feedback are greatly appreciated.

this is an interesting find, Juan! Hmm.. this somehow insinuates that Google still heavily relies on links despite their recent pronouncements.
Great article! I think it will be important that SEOs moving forward not only utilize AI for everyday task efficiency, but take things to the next step and look for ways to evolve in the SEO space utilizing this powerful new technology within the multiple LLMs available.
Credible links will continue to be a key metric, and most importantly – first hand content!