

He descubierto la patente de Google para SGE, su buscador experimental con IA generativa. La patente titulada “Generative summaries for search results”, fue presentada el 20 de marzo, unas semanas antes del lanzamiento en beta de SGE.
En este post explicaré cómo funciona el sistema detrás de SGE, según esta patente.
Antes de empezar: a día de hoy no hay ninguna otra patente asignada a Google que hable sobre técnicas de IA generativa para ofrecer respuestas en un buscador.
Puede haber otras patentes sobre el mismo tema aún pendientes de aprobación, pero creo que este documento es muy relevante para el funcionamiento actual de Google SGE.
La patente describe cómo «usar selectivamente un gran modelo de lenguaje (LLM) para generar un resumen en lenguaje natural en respuesta a una consulta de usuario», lo que se ajusta bien a lo que vemos y sabemos sobre SGE hoy en día.
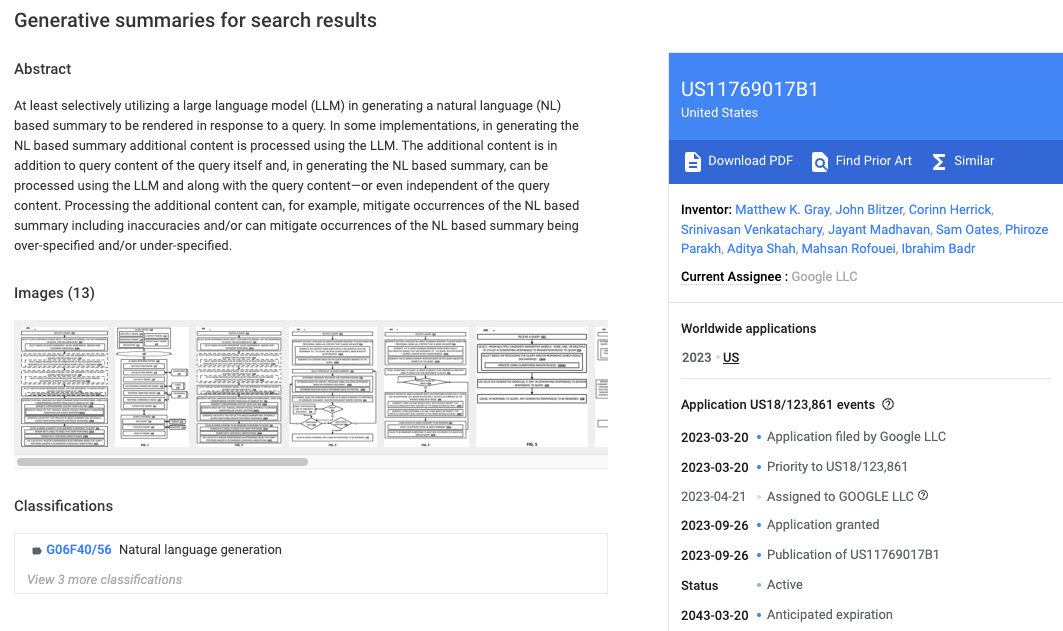
Pasos clave del proceso
Los pasos fundamentales de este proceso son:
1. Se parte de una consulta asociada con un dispositivo. La consulta puede ser ingresada por un usuario o generada automáticamente basada en el contexto.
2. Se selecciona un conjunto de resultados de búsqueda (SRDs) que respondan a la consulta y a consultas relacionadas o recientes.
3. Se generan snippets o fragmentos de contenido de cada SRD. Esto puede incluir texto, imágenes, vídeo, etc. El contenido puede ser seleccionado en base a la correlación con las consultas.
4. Se procesan los fragmentos de los SRDs con un LLM para generar un output.
5. Se genera un resumen en lenguaje natural a partir del output LLM.
Esto aprovecha la capacidad del LLM mientras lo limita al contenido de los resultados de búsqueda, para evitar alucinaciones.
6. Se muestra el resumen en el dispositivo, junto con resultados de búsqueda opcionales, anotaciones de confianza, enlaces a fuentes (los SRDs) que sirven para verificar, etc.
Uno o más modelos de lenguaje y de IA
Ahora, varios aspectos concretos que destacan en la patente y que son interesantes para SEO.
Por ejemplo, el hecho de que haya uno o varios modelos disponibles para generar a respuesta. Esto coincide con algo que Google afirma en su documento “An Overview of SGE”, publicado al mismo tiempo que SGE, pero sobre lo que no teníamos más detalles. Ahora, gracias a la patente, ya tenemos más información sobre el cómo y el por qué de esto.
1. Hay varios modelos generativos candidatos disponibles, incluyendo múltiples LLMs y otros modelos, como modelos text-to-image.
2. Tras analizar la consulta y los resultados de búsqueda, se selecciona uno, ninguno o varios de los modelos candidatos para generar la respuesta.
3. La selección puede basarse en:
• El procesado de la consulta con un clasificador para predecir los mejores modelos
• Detectar ciertos términos en la consulta para indicar modelos adecuados
• El tipo y contenido de los resultados de búsqueda para determinar modelos apropiados
4. Al seleccionar modelo, se busca un equilibrio entre precisión y uso de recursos. El sistema puede preferir LLMs más pequeños, a no ser que uno más grande sea mejor para la consulta.
5. Si se seleccionan múltiples LLMs, se pueden presentar múltiples respuestas, una con cada LLM.
Verificación de la información mediante enlaces a las fuentes
La patente también proporciona algunos detalles sobre cómo funcionan los enlaces a las fuentes:
En algunas implementaciones, cuando se muestra el resumen en lenguaje natural, se pueden incluir enlaces hacia los SRDs, que sirven para verificar partes del resumen.
Por ejemplo:
1. «Una parte del resumen, respaldada por un primer SRD, puede ser seleccionable (y opcionalmente subrayada, resaltada y/o anotada). La selección del fragmento puede resultar en mostrar un enlace hacia el primer SRD.»
2. Las partes del resumen con enlaces ayudan a los usuarios a ver rápidamente qué partes del resumen son verificables y acceder al contenido verificador, y también «encontrar rápidamente información de apoyo y/o adicional relacionada con ese fragmento.»
3. Los enlaces pueden ser enlaces generales a los SRDs o enlaces específicos al fragmento del resultado que proporciona la verificación.
4. Los fragmentos con enlaces pueden determinarse en base a la comparación del contenido del resumen con el contenido de los SRDs usando encoders.

Puntuación y anotaciones de confianza
Otra parte muy interesante de la patente trata sobre las anotaciones de confianza.
Creo que aún no las hemos visto en SGE, al menos yo aún no, pero Google lanzó una característica similar para Bard el pasado septiembre, el botón «Comprobar respuesta».

Así funciona la “confianza”, según la patente:
1. Se pueden generar puntuaciones de confianza para partes del resumen o para el resumen en su totalidad. Estas puntuaciones se utilizan para determinar qué anotación de confianza de un conjunto de candidatas debería aplicarse.
2. Las medidas de confianza pueden basarse en:
• La confianza del LLM reflejada en la salida del LLM.
• La confianza en los documentos de resultados de búsqueda (SRDs) que verifican partes del resumen.
3. Se puede anotar un resumen en lenguaje natural con una anotación textual de «alta confianza», «confianza media» o «baja confianza» en su totalidad. Cada una de las partes del resumen puede ser anotada con un color correspondiente que refleje un grado de confianza en esa parte.
Creo que esto es exactamente lo que está haciendo Bard en este momento, con verde para «alta confianza», ningún color resaltado para «confianza media», y naranja para «baja confianza».

Cómo encontré la patente
Ahora, os cuento cómo descubrí esta patente, que aún no había visto nadie, y otra cosa interesante: el nexo entre Google SGE y los Fragmentos Destacados.
Entre los documentos publicados en el juicio contra Google había un correo electrónico de John Gianandrea (ex Senior VP de Google), en el que mencionaba una contribución clave de un ingeniero llamado Steven Baker.
Como no me sonaba, busqué a Baker en Linkedin. Según su propio CV, trabajó en SGE en Google entre noviembre de 2022 y septiembre de 2023.

Ahora es Google Fellow, el escalón más alto en la escalera para los ingenieros de Google, al que llegan gracias a «logros sobresalientes y consistentes».
10 años antes en Google, Baker estuvo a cargo de «responder todas las preguntas del mundo (algorítmicamente)», un proyecto que internamente conocen como WebAnswers (y que los SEOs conocemos como Fragmentos Destacados).
Steven trabajó junto con Srinivasan Venkatachary en WebAnswers.
Sus carreras posteriores fueron muy similares: ambos fueron a Apple, donde trabajaron en Búsqueda y Siri, y regresaron a Google a finales de 2022 para trabajar en SGE.
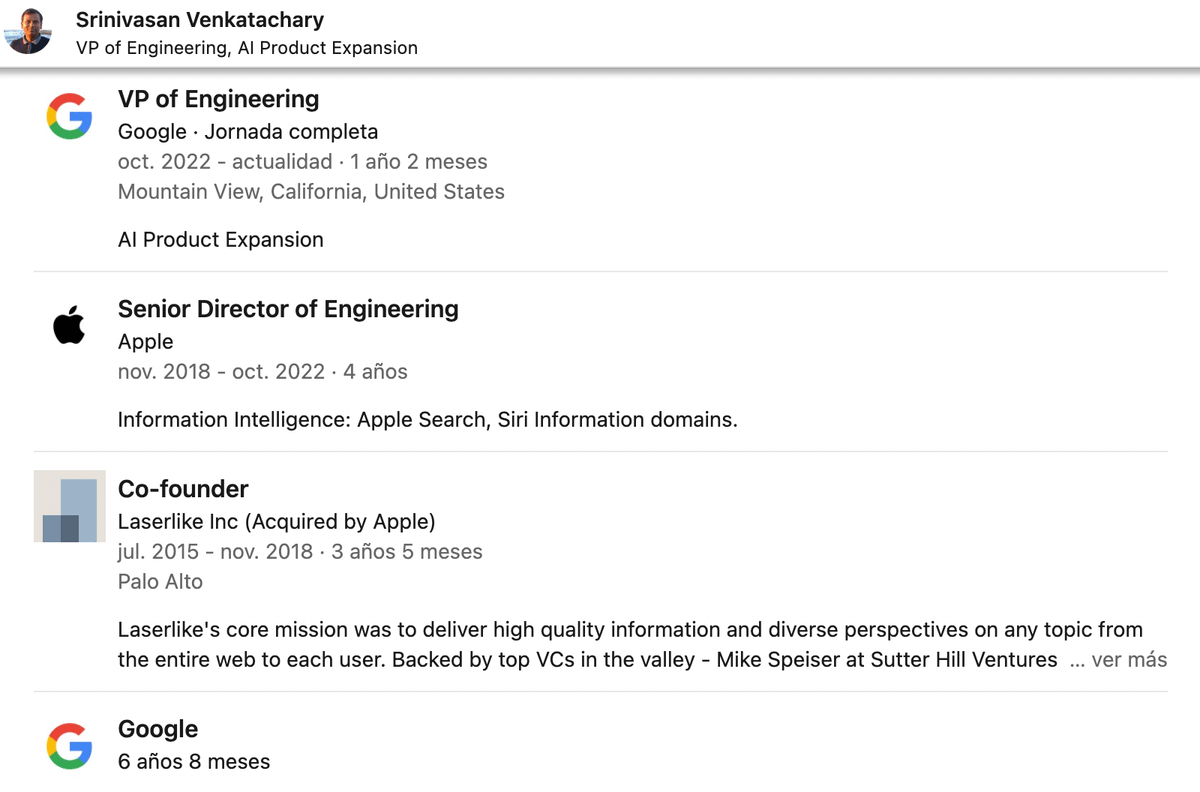
Entonces… ¿cómo encontré la patente? Decidí buscar patentes de cualquiera de estos dos ingenieros y ahí estaba.
Así que al menos dos ingenieros que trabajan en SGE habían sido clave hace alrededor de 10 años en el desarrollo de los Featured Snippets (WebAnswers) en Google.
Creo que esta es la razón por la que algunos SEOs han visto semejanzas entre los snapshots de SGE y los fragmentos destacados que podemos encontrar actualmente en Google.

Me gusta tanto el artículo como una innecesaria renovada confianza en tu investigación, se agradece mucho Juan, un saludo, Á.
Gracias, Álvaro! Un saludo!
Muy interesante el articulo, me ha gustado mucho