

El update de Google del pasado 9 de marzo ha sido el primer update al core (núcleo) del algoritmo confirmado oficialmente por Google desde la aparición de RankBrain (finales de 2015).
Los efectos del update han sido visibles, pero difíciles de aislar e interpretar. ¿Es la “calidad” del contenido? ¿Es su algoritmo machine learning haciendo de las suyas?
Uno de los efectos que he podido comprobar (dentro de lo que permite mi muestra limitada de datos, claro) es que Google ha mantenido o subido a los resultados que demostraban tener un mejor CTR.
Lo cual no es extraño, ya que en el fondo ese es el objetivo de Google: satisfacer lo más posible al usuario. Pero siempre es bueno tener pruebas, o al menos indicios.
Ojo, con este post no pretendo desvelar de manera infalible todo lo que ha cambiado Google con este update, ni dar el remedio milagroso para rankear en lo más alto.
Si acaso, en este post encontrarás indicaciones de lo contrario: que cada día es más difícil posicionar bien en Google con truquitos o métodos automatizables. Simplemente, voy a compartir un patrón que he encontrado y creo que contrastado lo suficiente.
Pero si alguien tiene datos que digan algo distinto, estaré encantado de que lo comparta en los comentarios, y así entre todos podremos aprender algo más sobre este update de Google, del que en mi opinión muy poco concreto se ha dicho hasta ahora.
El anuncio oficial de Google (12 de marzo)
El anuncio oficial del update llegó el 12 de marzo, a través de Danny Sullivan, nuevo Google Search Liaison (contacto entre Búsqueda de Google y los medios). Su mensaje: que durante la semana anterior habían lanzado un “broad core algorithm update” (amplia actualización del núcleo del algoritmo).
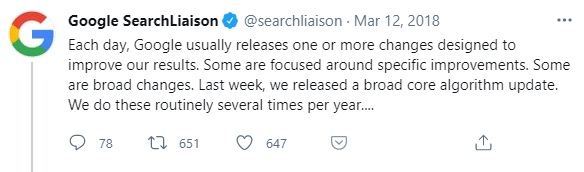
Para mí, lo más importante venía en el segundo tuit del hilo: “Some sites may note drops or gains. There’s nothing wrong with pages that may now perform less well. Instead, it’s that changes to our systems are benefiting pages that were previously under-rewarded”.
Traducido: “Algunos sitios pueden notar pérdidas o ganancias. No hay nada malo en las páginas que ahora posicionan peor. Simplemente, los cambios al sistema están beneficiando a páginas que anteriormente no se estaban posicionando tan bien como deberían”.
Es decir, deja claro que si notamos pérdidas de visibilidad no se debe a ninguna penalización, sino que se debe a que páginas que hasta ahora no habían sido debidamente rankeadas por su algoritmo nos han arrebatado el puesto, y con toda justicia.

De todo esto saco que:
- Google reconoce que los factores de su algoritmo (al menos hasta marzo de 2018) podían estar rankeando páginas que merecen estar en las primeras posiciones menos que otras
- Para esto, deben manejar datos que les indiquen la satisfacción de los usuarios con los resultados antes y después del update, y esos datos no pueden ser otros que el CTR y el dwell time (tiempo de permanencia en el resultado antes de regresar a la SERP).
Hasta ahora, todo esto que digo lo sabe más o menos cualquier SEO, y además es muy poco concreto… Al fin y al cabo, eso es lo que se supone que hace Google todos los días, ¿no?
Pero, ¿y si te mostrase indicios razonables de que Google ha actuado exactamente así durante este update? ¿Y si te dijese el umbral aproximado de CTR que Google considera una respuesta de usuario correcta, y por debajo del cual ha actuado con su core update del 7 de marzo?
¿Será posible lo que digo? Vamos a verlo con ejemplos concretos.
Análisis del update: ejemplos de cambios en los rankings
Empiezo por un ejemplo que no es mío, y que de hecho parte de datos mucho más completos que los míos, ya que parte de los datos de Pi Datametrics, una herramienta que mide la visibilidad orgánica.
El ejemplo de Pi Datametrics
En este post en Search Engine Watch, Jon Earnshaw de Pi Datametrics muestra a las claras las fluctuaciones que se dieron durante las 6-7 semanas anteriores al update en la SERP de una búsqueda competida.
En concreto, la búsqueda es “What’s the best toothpaste” y el mercado analizado, UK. Según Ahrefs, esta query se busca 60 veces al mes en Reino Unido, por lo que no estamos hablando de un volumen más bien discreto.
En la imagen vemos el “bailecito” que se marcaron 7 resultados del Top 20 en las semanas previas al update, y las posiciones que acabaron ocupando cuando se calmó la cosa, un par de semanas después del update principal.
Resumen: todos ellos acabaron un par de posiciones por debajo cuando se estabilizó la SERP.
Quizá lo más destacable de este ejemplo es que durante los días de “Google Dance” algunos de estos resultados no perdieron sólo unas pocas posiciones, sino que algunos pasaron de Top 5 a desaparecer directamente del Top 100.
Nota: me guardo este ejemplo para enseñárselo a algún cliente la próxima vez que entre en pánico cuando una keyword baje un par de posiciones. 😉
Un par de observaciones en base a este ejemplo:
- A los updates a gran escala les precede un período de inestabilidad en el que Google parece estar probando, bajo nuevos criterios, a todos los posibles candidatos, incluyendo algunos resultados que ni siquiera figuraban en el Top 100 antes de iniciarse los cambios. Esta inestabilidad se ha visto ya muchas veces con updates anteriores, pero que yo sepa nunca antes había durado tanto el período de cambios, ni había afectado a resultados tan alejados del Top (aunque de nuevo, sin datos muy completos para cada update es difícil saberlo a ciencia cierta)
- El factor determinante en el nuevo update parece ser la satisfacción del usuario con el resultado, ya que tras el periodo de pruebas fueron descartados resultados con mucha autoridad (Business Insider, Amazon.com) pero que sin embargo no tienen un contenido dirigido exclusivamente al público de UK. Desgraciadamente, aquí no tenemos datos de CTR de cada uno de los resultados de la SERP
- Lo único que no me cuadra es que Google, por muy “machine learning” que sea, saque conclusiones del comportamiento de los usuarios tan rápido, ya que si “what’s the best toothpaste” sólo da 60 impresiones al mes, a algunos resultado los ha descartado tras darle sólo unas 20 oportunidades para probar que son una buena respuesta a la pregunta del usuario. Me parece poco, y me lleva a preguntarme si Google / RankBrain no está analizando globalmente tipos de búsquedas y buscando páginas que cumplan con un determinado patrón, que ha decidido es el más adecuado para responder a esas búsquedas.
Así pues, del ejemplo de Pi Datalytics ya podemos sacar un primer patrón del update, o mejor dicho, algo que precedió al update: Google agitó las SERPs de todas las queries durante las semanas anteriores a la actualización.
¿Todas? ¡No! Hay un tipo de búsquedas en las que no se dio este frenético baile de posiciones en las semanas previas al update, y te lo voy a demostrar con datos en mis próximos ejemplos.
Vamos allá:
Ejemplos de “mis sitios”
Voy a contrastar todo esto con lo que he encontrado en sitios que gestiono o que son de mi propiedad (tengo acceso a los perfiles de Google Search Console de 33 dominios activos y con algún tráfico orgánico).
Fluctuaciones en las SERPs
Primero vamos a confirmar que, en efecto, en las semanas anteriores al update, se dio una volatilidad similar a la que registraba el caso de Pi Datametrics.
Ahí van 7 pantallazos de Google Search Console, para 7 queries distintas en las que la página que ocupaba la primera posición fue desplazada durante las semanas anteriores al update (aunque luego volvió al Top 1).

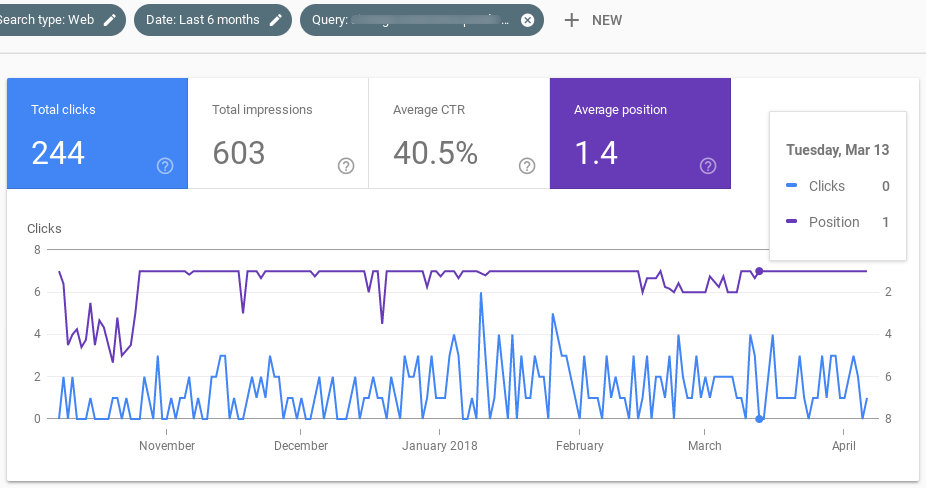

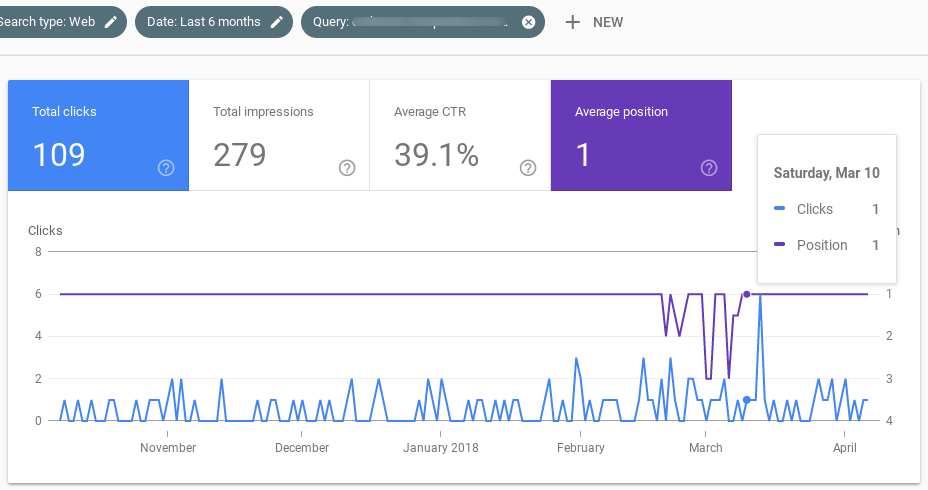
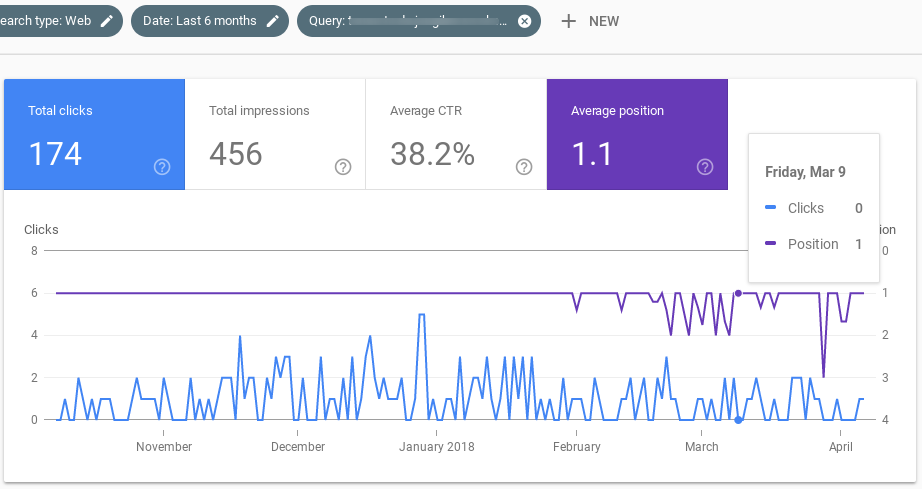

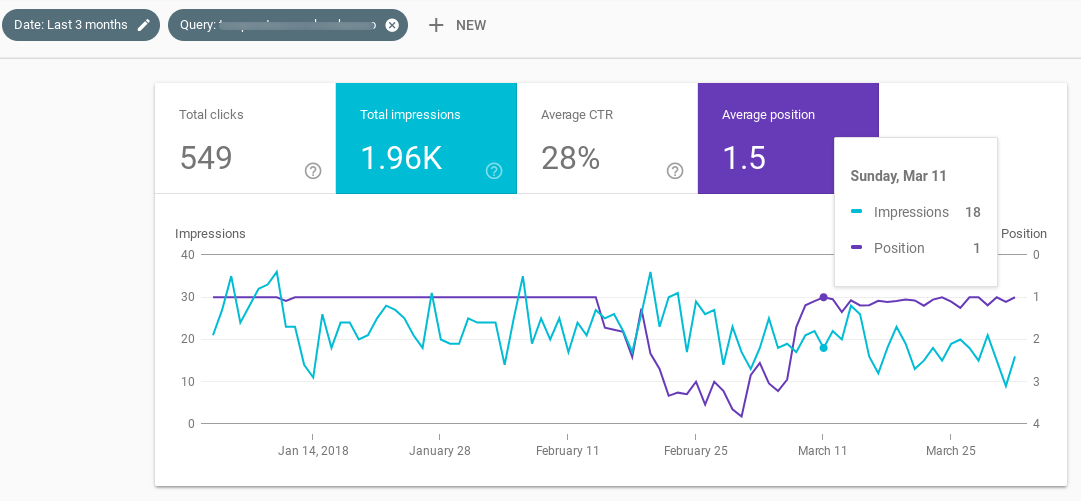
La cosa, por tanto, se confirma.
Una aclaración: tanto para estos ejemplos, como para los del siguiente punto, estoy dejando fuera sitios en los que se cambió algo en las semanas anteriores al update (Title o contenido) o hacia los cuales estuviera creando enlaces (internos o backlinks) en ese mismo periodo.
Así podemos estar seguro de que los movimientos de posición se deben a cambios de Google, y no a cambios hechos en la página por nosotros mismos (al fin y al cabo, si ya estaba en número 1 para esas búsquedas, ¿para qué cambiar nada?)
También estreché un poco más el círculo al dejar fuera todas las búsquedas que no tuvieran como mínimo un volumen de impresiones cercano al del ejemplo de Pi Datametrics. Por tanto, dejé fuera las queries con menos de 40 impresiones al mes.
Y por último una observación, con respecto al ejemplo de Pi Datametrics:
En estos ejemplos, el período de pruebas varía según la query. No siempre se inició seis o siete semanas antes del update, de hecho en algunos casos sólo duró un par de semanas.
Como esta diferencia de duración no está relacionada con el número de impresiones de la búsqueda, la única explicación que le veo es que varíe según el grado de competencia de cada SERP.
Es decir, puede que la de “…best toothpaste” sea una query con mayor competencia a nivel orgánico que las de mis ejemplos que sólo muestran fluctuaciones en 2 o 3 semanas.
¿Qué quiero decir con más competencia orgánica? Pues muchas páginas con alta relevancia para esa búsqueda y con alta autoridad. Si Google tiene más resultados entre los que “desempatar”, es lógico que le lleve más días probar el CTR de todos los posibles candidatos en los días previos al gran update.
SERPs con el Top 1 estable a lo largo de febrero y marzo
Pero sigo. Una vez confirmado el patrón, me interesaba saber si podía encontrar alguna excepción.
Es decir, buscaba resultados Top 1 que se hayan mantenido inamovibles en sus posiciones para una query concreta durante el período de pruebas y tras el propio update. Eso querría decir que Google considera que no hay necesidad de mover el Top de esa SERP (porque ya responde bien a la búsqueda del usuario).
Por supuesto, había que descartar búsquedas de marca, por lo que mi investigación se limitó a buśquedas genéricas.
¿Y qué encontré? Esto:

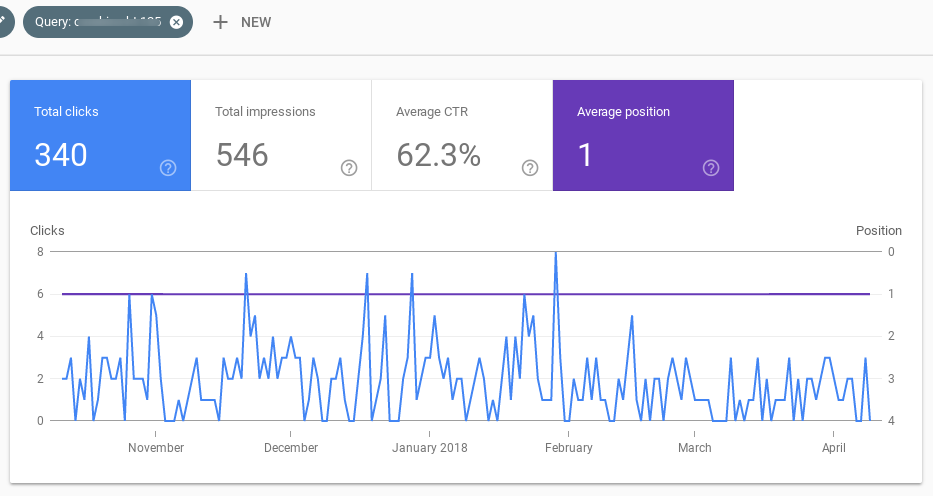

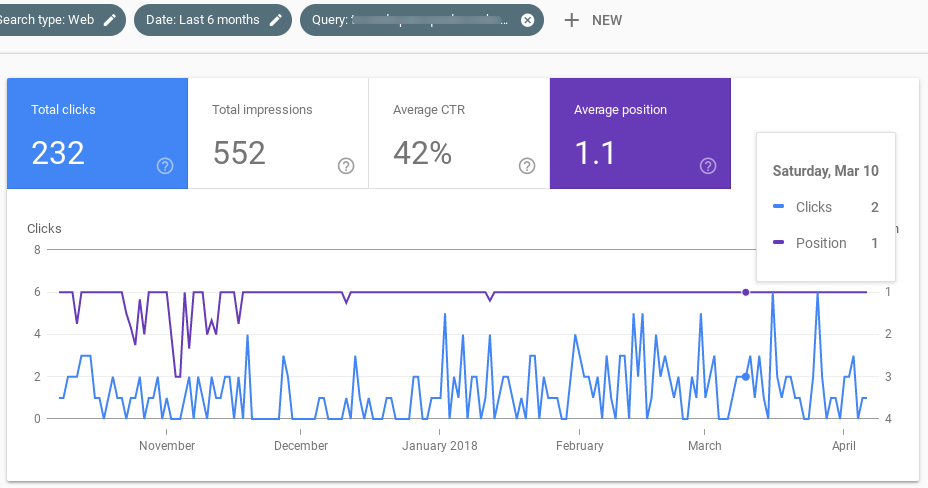
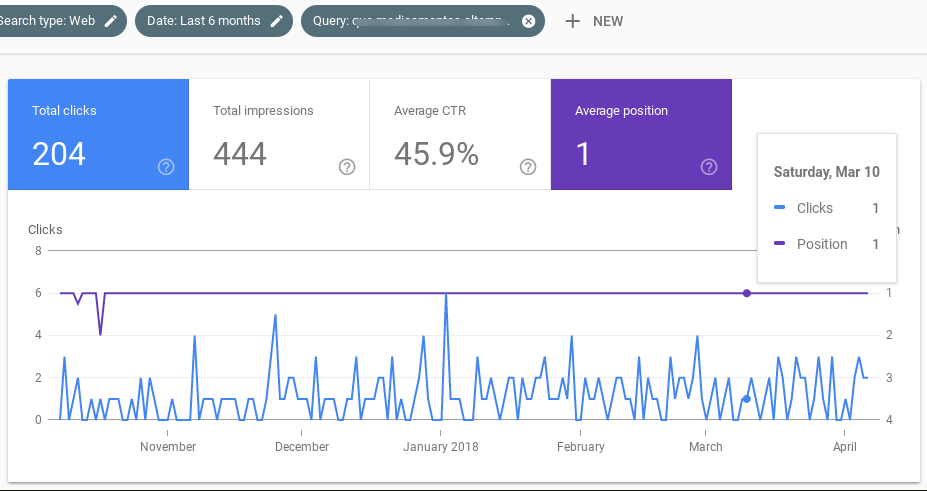

Aquí puedes ver 6 ejemplos diferentes (aunque tengo más) de resultados que se han mantenido constantes en su posición 1 y a los que Google (al menos según los datos que comparte con nosotros en Search Console) no ha hecho rotar con otros resultados durante las semanas previas al update de marzo. De hecho, para estos resultados es como si el update de marzo no hubiera existido.
¿Qué tienen en común? Un CTR inusitadamente alto, en todos los casos por encima del 40%, que es más alto de lo normal para un resultado en posición Top 1.
Antes de seguir, ¿sabemos cuál es el CTR promedio para cada posición en Google? Pues tenemos varios estudios en los últimos años.
Según de cual nos fiemos más, el CTR promedio para la primera posición orgánica oscila entre el 31% (estudio de Advanced Web Ranking de 2014) y el 20.5% (estudio de Ignite Visibility de 2017).
Parece innegable la tendencia de que con los años baja el CTR medio de todas las posiciones, dado que Google insiste en meter cada vez más featured snippets, módulos de Google Shopping, carruseles y demás parafernalia que afecta claramente al CTR de los resultados orgánicos.
Siendo conservadores, digamos que un CTR bueno para un Top 1 hy en día puede ser, de media, un 25%. Los casos que yo he puesto arriba son los más extremos de los que me he encontrado.
Mi reacción inicial fue pensar que había una especie de “línea divisoria” en torno al 40% de CTR. Entre todos los ejemplos que me he encontrado, el 90% de los que han permanecido estables tenían un 39% de CTR o más. Y el 90% de los que han sido sometidos a un periodo de fluctuaciones por Google tenían un 41% o menos.
Pero como todo con Google, no es tan sencillo. Mirando mucho, he encontrado un 10% de resultados que no sigue esta regla. Por ejemplo:


Aun y así, tanto el 27% de CTR como un 21,6% podrían considerarse “buenos”, según la query, ya que el estudio de 2017 fija el CTR promedio en 20,5%.
Y la verdad es que pienso que el tipo de query es la clave. Más concretamente, el patrón de CTR que se da entre los 10 resultados de la SERP.
Para empezar, hay queries que reciben mayor porcentaje de clicks que otras. En muchas queries, al usuario le basta con ver los títulos y descripciones de los resultados, y ya no necesita hacer clic en ninguno. En otras, en cambio, el usuario suele hacer clic en tres o cuatro resultados por cada query, porque con un resultado no le vale y quiere comparar con otros (las búsquedas de investigación antes de hacer una compra son un claro ejemplo).
Y luego, los distintos features que está metiendo Google en las SERPs también afectan mucho al CTR. Si la SERP tiene varios features o rich results, especialmente si es featured snippet, módulo mapa o módulo shopping, el CTR cae por los suelos.
Así pues, un CTR de 35% puede ser buenísimo, inmejorable, para ciertas queries, y no tan bueno para otras. Es ahí donde creo que está la clave para decidir si un resultado tiene el mejor CTR posible o aún es mejorable.
Esos datos, desgraciadamente, sólo los conoce nuestro amigo Google, aunque veo una utilidad grandísima para el SEO en una herramienta que fuera capaz de estimar los CTRs medios por cada tipo o intención de búsqueda (pista para Sistrix, Ahrefs, Semrush, etc) 😉
¿Qué dicen las patentes de Google sobre el CTR?
Antes de acabar, ¿tiene todo esto alguna base según las patentes de Google? ¿O es pura especulación mía, y no hay forma de saber si Google ha tenido en cuenta alguna vez?
Bueno, teniendo en cuenta que nunca sabemos a ciencia cierta si Google aplica o no las tecnologías e ideas que ha patentado, lo que sí puedo decir es que hay al menos una patentes que toca cuestiones cercanas a lo que he contado hasta ahora.
Modifying search result ranking based on implicit user feedback and a model of presentation bias: https://patents.google.com/patent/US8938463B1/en (presentada en marzo de 2007 y concedida en enero de 2015)
No voy a comentarla en detalle porque me tiraría varias horas. Pero haré un resumen, algo esquemático, eso sí:
La patente da un sistema para estimar el CTR de cada resultado de una query de forma independiente, descontando su posición y cualquier elemento de la presentación de ese resultado que pueda influir en que el CTR sea mayor o menor.
El objetivo es eliminar o reducir la incidencia que tiene sobre el CTR de un resultado la posición que ocupe en la SERP (presentation bias). Así, Google obtiene datos del CTR “real” de cada resultado, independiente de su posición o aspecto al ser presentado como un resultado al usuario – y puede modificar el ranking de la query de acuerdo a esos CTRs reales, no contaminados por el contexto. Con ello, acabarían más arriba los resultados con mayores posibilidades de recibir clicks.
Creo que es algo muy parecido a lo que he descrito con mi pequeño “descubrimiento”, aunque en ningún caso pretendo que esta patente sea el único mecanismo usado por Google en el update de marzo.
De hecho, estoy bastante seguro que si lo ha usado no es más que uno entre muchos otros métodos para asegurar la calidad de los resultados y la satisfacción del usuario.
Sé que todo esto es muy incompleto, porque para empezar sólo estoy hablando de CTR, y no de dwell time o long clicks vs short clicks, que es el tiempo que pasa el usuario en tu web antes de volver a la SERP, y que, por cierto, hay otra patente anterior que habla de ello y cómo usarlo para modificar los rankings:
Modifying search result ranking based on implicit user feedback: https://patents.google.com/patent/US8661029B1/en (presentada en noviembre de 2006 y concedida en febrero de 2014)
Pero me doy por contento con los datos que he encontrado y que, en mi opinión, confirman lo que siempre nos ha parecido obvio a muchos: que un CTR excepcionalmente bueno puede “pasar” por encima de las señales de autoridad y relevancia y colocarte en los primeros puestos de una SERP
Por supuesto, si crees que estoy equivocado y tienes datos que muestren que los tiros van por otro lado, acepto y espero tu comentario. Como digo, comparto todo esto para que entre todos aprendamos algo, no para decir “yo tengo razón”.
Conclusiones de mi análisis: ¿qué puede sacar un SEO de todo esto?
Sé que en mi post hasta ahora hay pocas cosas 100% concretas y accionables, y que eso es lo que más le interesa a cualquiera que se está pegando diariamente con Google.
Así que voy a tratar de concretar en unas cuantas conclusiones:
No entres en pánico, es un update
Si Google te baja un par de posiciones (o varias decenas) en una búsqueda, no entres en pánico y no empieces a cambiar cosas como pollo sin cabeza. Sé que esto especialmente a los clientes le va a costar entenderlo, pero el ejemplo del principio de Pi Datametrics lo deja bien clarito.
Es perfectamente posible desaparecer del Top 100 durante un par de semanas y luego volver más o menos a tu posición anterior. No has hecho nada mal, son “cosas” de Google.
Hombre, si algo has hecho mal es que no respondes al 100% a lo que busca tu usuario, al menos no respondes tan bien como los resultados que Google deje por encima de ti una vez pasado el update.
Analiza a fondo y optimiza, una vez que las SERPs se han calmado
Cuando las SERPs se estabilizan es cuando hay que analizar en profundidad y tomar decisiones. Los que han quedado por encima de ti no están sólo ahí por tener más links o mayores señales de relevancia, al menos no siempre.
Pueden estar ahí sencillamente porque su contenido responde mejor, de manera más completa o más rápido a lo que busca el usuario. Analízalos y decide si puedes mejorar lo que ofreces al usuario, teniendo muy en cuenta la búsqueda (o mejor dicho, la intención de la búsqueda).
La intención de búsqueda es lo que de verdad importa
Hay veces en las que no podemos mejorar, porque nos hemos emperrado en una búsqueda a la que no podemos responder. Por ejemplo, una búsqueda local, si nuestro negocio no está donde el usuario busca.
En esos casos, es natural y yo diría que innexorable desaparecer poco a poco de la SERP. Google lo está supeditando todo a la intención de búsqueda, hasta el punto de que está creando SERPs muy distintas, según el user intent o la intención que infiere en en cada búsqueda.
Importante para las webs de afiliados: lo que he dicho vale también para páginas informativas en queries que son transaccionales (ejemplo: comprar sábanas). Google no quiere posicionar a un “falso” ecommerce que lo único que hace es listar el producto y luego dirigir hacia la tienda donde realmente se vende. Quiere rankear directamente a la tienda, y pienso que a la larga lo va a hacer con un 99% de efectividad.
También es cierto que en las búsquedas puramente de transacción, un gran porcentaje del CTR se lo está llevando el módulo de Shopping, y si tienes una web de afiliados nunca vas a poder estar ahí.
Ojo, no estoy diciendo que las webs de afiliados estén condenadas y que ya nunca más generarán ingresos. Al contrario, estoy diciendo que centres el tiro. Las intenciones de búsqueda en las que tienes muchas más posibilidades de rankear bien son las puramente informativas, o las de comparación.
A cada tipo de query le corresponde un tipo de resultado. Analiza patrones en Google, mira cómo es la SERP, mira qué tipos de páginas están rankeando… Y adapta a eso tu contenido. Es la única forma de aspirar a CTRs “a prueba de updates”, del 40% o 60%, como algunos de los que he mostrado en mis ejemplos.
En fin, hasta aquí he llegado. Ahora espero comentarios, matices y sobre todo datos de otros, si queréis compartirlos (especialmente si alguien tiene ejemplos de páginas en Top 1 con muy buen CTR y que hayan caído). Mi objetivo no es demostrar que tengo razón, sino aprender más sobre Google.
Por cierto, si queréis un estudio muy distinto sobre los efectos del update de marzo, a nivel global en lugar del mío, que ha sido caso a caso y partiendo sólo de mis datos, no dejéis de leer el análisis de Sistrix.
¡Gracias por leer, y hasta el próximo update!

El modo pánico de los clientes es intratable XD, un genial estudio Juan, con datos, no solo con suposiciones. En el SEO la seguridad al 100% ya sabemos que es imposible, pero si es verdad que las gráficas son bastante claras.
Sobre el CTR también queda claro que ha mayor porcentaje mejor rankeas, y eso está muy bien porque para mejorar el CTR influyen muchas cosas que podemos mejoras.
Saludos!
Muchas gracias por comentar, José Luis. Sí, la verdad es que le temo mucho más al «modo pánico» de un cliente, que a los updates de Google!?
Hola, yo no entiendo mucho de esto pero tiene sentido lo que dices, ya que para una búsqueda determinada mi web aparece encima de una web monstruosa que no pensaba superar nunca, y es que optimicé el título y la meta para hacerla más atractiva, subió el CTR y la posición, lleva así como 3 o 4 semanas, ojalá siga así, esto me ha hecho darme cuenta de la importancia de la apariencia en las SERPS y que no todo son enlaces y autoridad. Obviamente si luego la web no responde a las espectativas volverá a caer digo yo..
Hola, Javi, muchas gracias por comentar. Básicamente es así, Google busca los resultados más útiles y efectivos para los usuarios, no las webs más grandes o que llevan más tiempo en esto. Tienes razón en decir que si tu la web no cumpliera las expectativas podría acabar bajando, pero si piensas bien en la intención del usuario que está haciendo esa búsqueda, no hay razón por la que no puedas darle una buena respuesta. La mayoría de las intenciones de búsqueda son relativamente fáciles de cumplir, por así decirlo es una proposición sí / no, mientras que el CTR es un continuo, que va del 0 al 100% y casi siempre se puede mejorar.
Por último, es cierto que no todo es autoridad y enlaces, pero tampoco lo descuides. La autoridad y los enlaces es como Google, y los usuarios, tienen más oportunidades de acabar conociendo o llegando a tu web. También hay que trabajarlo, aunque no vale con crear enlaces y pasar totalmente del usuario. Las webs son para los usuarios, y Google quiere satisfacer a los usuarios, no a su algoritmo.
Un saludo y de nuevo gracias por leer y comentar. 🙂
Cada vez tengo más claro que las webs de afiliados son de dos tipos:
1. Informacionales con algún producto incrustado en medio del texto.
2. Puro ecommerce con texto escondido donde puedas meterlo, sin molestar al usuario.
He visto resultados bailando y otros estables pero tiene todo el sentido del mundo lo del CTR. Lo que se deja ver en cada movimiento de Google (y me encanta) es que por encima de todo influye el comportamiento del usuario.
Al igual que en Adwords utilizan un score que no valora enlaces, quién sabe si el Relevance Score orgánico será similar, sin enlaces, solo teniendo en cuenta anteriores comportamientos de usuarios.
Como anécdota: me han subido un par de webs de afiliados. Aunque no están planteadas como e-commerce, sino como contenido.
Álvaro! Muchas gracias por pasarte a comentar. Lo de Adwords yo lo he pensado muchas veces, no llego al extremo de pensar que usen exactamente el mismo método (hay muchas variables en SEO que en Adwords no están presentes), pero en líneas generales el sistema para calcular la relevancia y el rankscore de un anuncio es aplicable para un resultado orgánico.
Y gracias por compartir tu dato de las webs de afiliados que han subido para queries de contenido (entiendo que informativas o comparativas). Lo que molaría sería hacer un estudio similar al que he hecho, pero para una serie de queries y resultados que sean del mismo tipo (pero obtener todos los datos y coordinarlo pueden ser muchas horas de curro) 😉
Hola Juan. Un post bien completo, explicado y justificado en datos. Enhorabuena!!!
Pd.- Échate una siesta ; )
Jaja, lo haré, cuando se pongan de acuerdo para darme un respiro todos mis clientes, Google… y mis hijas. ;D
Muchas gracias por el artículo, Juan. Me ha resultado muy clarificador.
Buenísimo el análisis, Juan!
Creo que nos va a servir a más de uno para apaciguar el modo pánico jajaja. Con el argumento de «mira hombre, que no solo te ha pasado a ti, que es Google que quiere darnos un infarto a todos» igual conseguimos algo 😉
Un abrazo!
He leído el post entero y está bien currado pero hay varias cosas que me chirrían:
1- Saco de la lectura que el cambio de googogoel da más importancia ahora al ctr que antes del 9 de marzo..
2- Esto es algo que hace ya años que se venía sabiendo y de hecho las googglgle dances eran para eso.
3- Sin embargo creo que la cosa a día 7 de junio no se ha estabilizado todavía, grunglel le ha metido un buen meneo a las serps y ha sacado mucha mierda del fondo del lago de las búsquedas. Creo que es una macro gosoosgle dance pero no de una semana, sino de varios meses (al menos 3 o más) como ya pasó en 2013 con el pingüinazo. Tengo varias webs subiendo en CTR y al mismo tiempo que bajan en posicionamiento lo que puede indicar que la gente baja más resultados porque los de arriba no sirven, aunque también se pierden muchos clics porque la gente abandona la búsqueda …
4- En cuanto a los datos de tu estudio me parecen muy poco relevantes, con tan poquísimos clics (54, 78, etc. de noviembre a abril) lo único que puede deducirse es que son keywors que nadie busca y es normal que si lograste el primer puesto nadie tenga interés por competir y quitártelo.
5- No es por joder, me ha gustado tu post, como escribes y el trabajazo que te has tomado pero con tan poquísimos clics y visitas no se puede deducir nada.
Me suscribo a tu blog a pesar de esto porque parece que algo se podrá aprender de tí si sigues con esas ganas.
Un saludo.
Hola Lorenzo, agradezco mucho tu comentario.
Estoy de acuerdo en casi todos los puntos, con algunas pequeñas salvedades.
1. Sí, pero no estoy seguro de si sólo le da más importancia, o si aparte también lo evalúa de forma más granular o más en «tiempo real», mientras que antes sus controles rutinarios de CTR por así decirlo eran menos frecuentes o precisos. Como muchas otras con Google, esto es algo que por ahora no podemos saber, y sólo podemos hacer una aproximación con los datos que nos da.
3. Efectivamente ha habido varias «oleadas» sucesivas de updates tras el inicial del 9 de marzo. Quizá las más claras han sido 16 de abril, 30 de abril y 10 de mayo (en algunos clientes este último ha revertido lo que se ganó en las semanas previas al update del 9 de marzo). a día de hoy efectivamente no sabemos si estos movimientos van a parar, o ya van a pasar a ser un nuevo «feature» de Google (pienso que esto último es posible).
4. Bueno, pero ahí estás hablando de «competencia SEO», y eso en mi opinión poco tiene que ver con actualizaciones del algoritmo de Google. Google se actualiza por igual para los términos más competidos a nivel SEO como para los menos, pueden tener filtros para evitar spam y las prácticas más agresivas SEO pero eso es todo, no les importa si para una keyword hay 30 sitios tratando de posicionarse o sólo 2. Por eso mi conclusión es que si ciertas queries reaccionan de manera diferente al mismo update, y lo que tienen de diferente es un CTR muy alto (dato objetivo y medible por Google) tiene que deberse a eso, y no a que sean queries poco competidas (dato no medible por Google y no relevante para su objetivo de servir mejores resultados al usuario).
De todas formas poco tráfico no es siempre sinónimo de poca competencia. Hay longtails con poco volumen y mucha conversión, y lógicamente están muy competidas. De hecho el ejemplo del principio del estudio de Pi Datametrics es una keyword con relativamente poco tráfico y mi ha competencia.
De nuevo muchas gracias por tu comentario y por suscribirte. 🙂 Si no lo has leído te recomiendo mi post sobre Intención de búsqueda, que trata temas relacionados y del que me gustaría también mucho saber tu opinión: https://useo.es/intencion-de-busqueda/
Me ha gustado el post.
Estaba buscando updates de google y me salio tu blog
felicidades por el SEO