

Qué es la URL Inspection API de Google
El pasado 31 de enero, Google permitió por fin el acceso por medio de API a sus datos de indexación de URLs en tiempo real.
Es decir, la misma información que proporciona la herramienta de inspección de URLs, incluida en la interfaz de Search Console en junio de 2018, pero en lugar de estar obligados a consultar estos datos manualmente y de una url en una, ahora con la API podemos hacerlo de manera automática y en masa, dentro de los límites de uso estipulados por Google.
Límites de la API de inspección de URLs
Los límites de la API son de 2000 solicitudes al día por propiedad (una url, una solicitud), y con una “velocidad” máxima de 600 solicitudes por minuto.
Sí, es una pena, 2000 requests al día es muy poco para sitios grandes, pero se puede aumentar activando una propiedad para cada carpeta del sitio, ya que el límite es por cada propiedad verificada, no por dominio.
Esto ha sido confirmado por Daniel Waisberg, del equipo de Search Console:

Qué datos proporciona
La información que nos proporciona la API para cada URL es la misma que podemos ver cuando usamos la herramienta de inspección de URLs en Search Console.
Al igual que esta herramienta, los datos proporcionados por la API no se limitan a informar del estado de indexación, sino que incluyen también si la URL pasa el test de usabilidad móvil y el test de resultados enriquecidos (y qué mejoras o resultados enriquecidos pueden mostrarse para esa URL).
Una imagen vale más que mil palabras y creo que se pueden entender perfectamente los campos y sus valores:
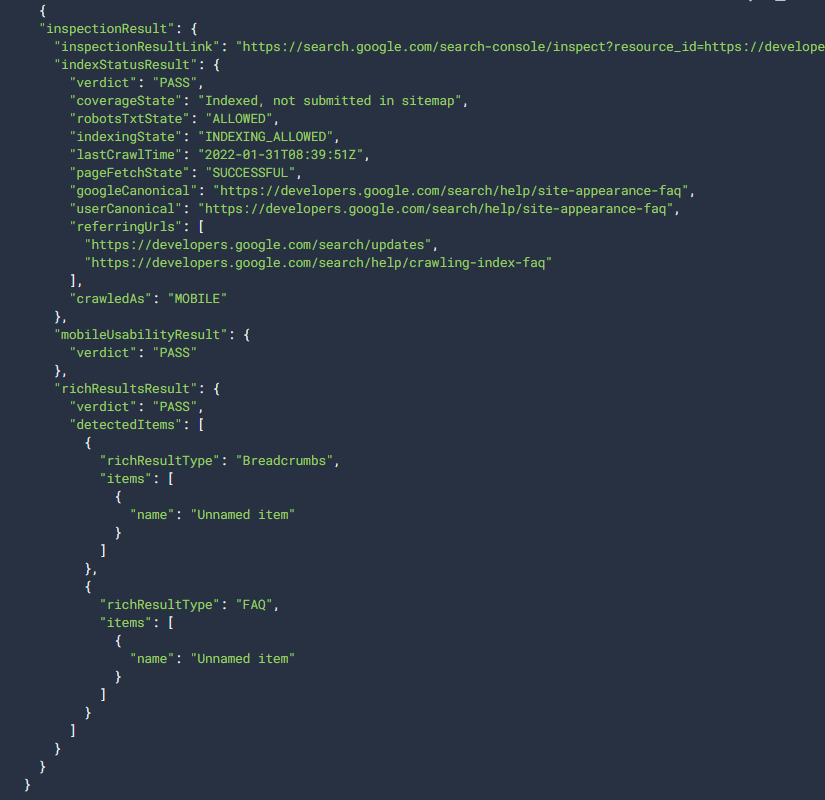
Para más detalles, recomiendo consultar la documentación de la API.
Cómo usar la URL Inspection API
Tenemos dos opciones para extraer la información que queremos de la API: directamente, haciendo llamadas a la API desde una línea de comando, o aprovechando las integraciones que ya han hecho varias herramientas de SEO, para hacer llamadas a la API desde sus interfaces e incluso dentro de sus procesos de trabajo (rastrea tu sitio con Screaming Frog o Sitebulb y aprovecha para extraer esta información).
Empiezo por las herramientas, ya que requieren menos tiempo de configuración:
Por medio de herramientas
Bulk Index Coverage Tool de Mydomain.dev
Veamos primero esta herramienta desarrollada por Lino Uruñuela, ya que es la más universal e incluso rápida de poner en marcha.
Para usarla, no necesitas descargarte nada, ni tener cuenta en ninguna herramienta (más allá de acceso de propietario a la propiedad de Search Console que quieras consultar).
Simplemente da permisos a la herramienta, copia y pega las URLs que quieras consultar y voilá, tendrás toda la info en este formato.
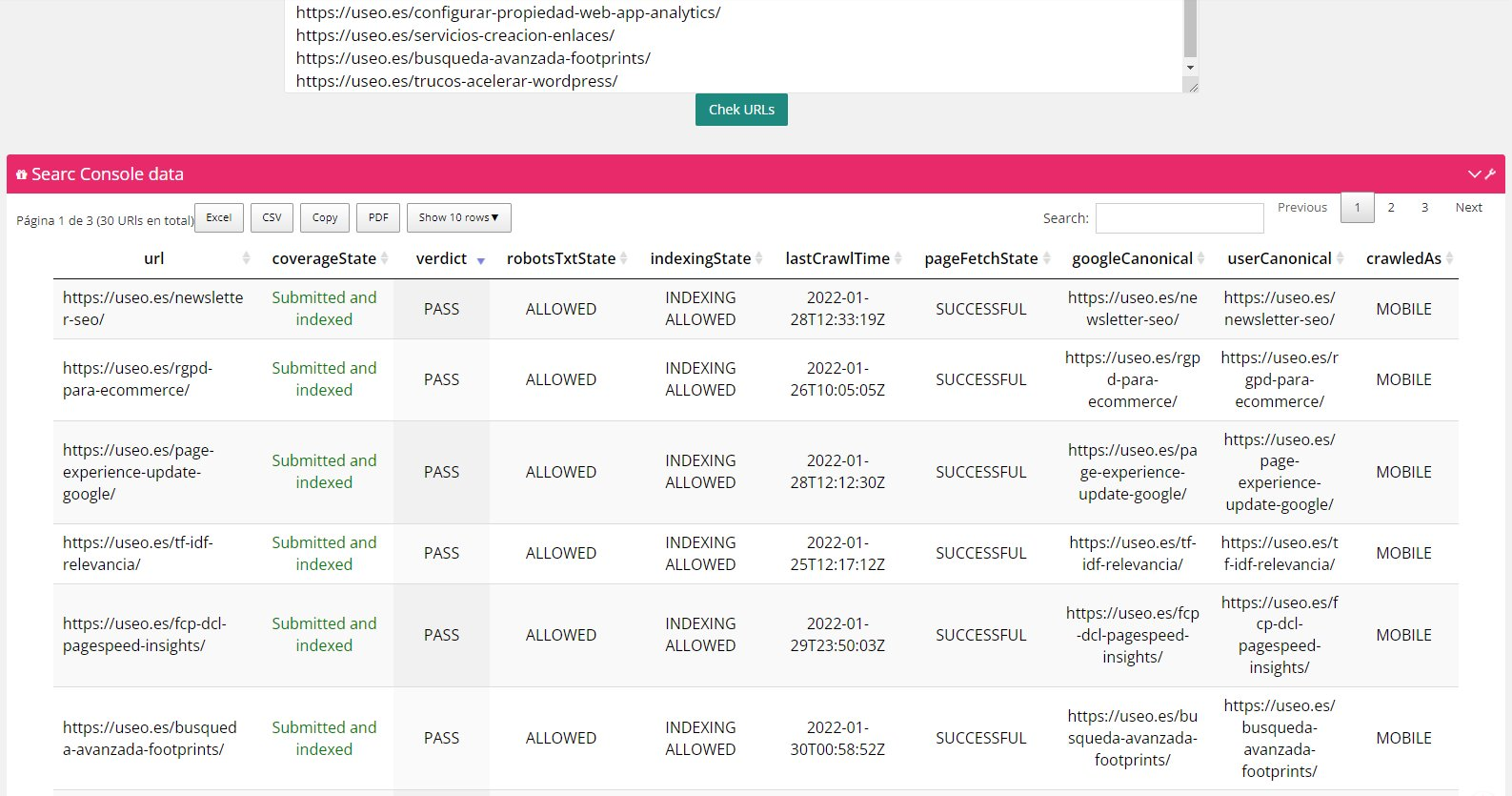
Puedes descargarlo o copiarlo para añadir a tus Excel o Sheets. Va bien y, lo que es mejor, muy rápido.
Nota: aunque por ahora no incluye el dato de la URL de referencia, Lino me ha dicho que lo incluirá en la próxima actualización de la herramienta.
Screaming Frog
Probablemente el crawler más popular, Screaming Frog ha sido también el primero en integrar estos datos (en menos de 48 horas desde el anuncio de Google ya lo tenían desarrollado).
Sólo debes autorizar acceso a tu cuenta de Google antes de hacer el rastreo (tal y como se hace por ejemplo para extraer datos de Google Analytics o de Pagespeed Insights) y elegir la propiedad a analizar.
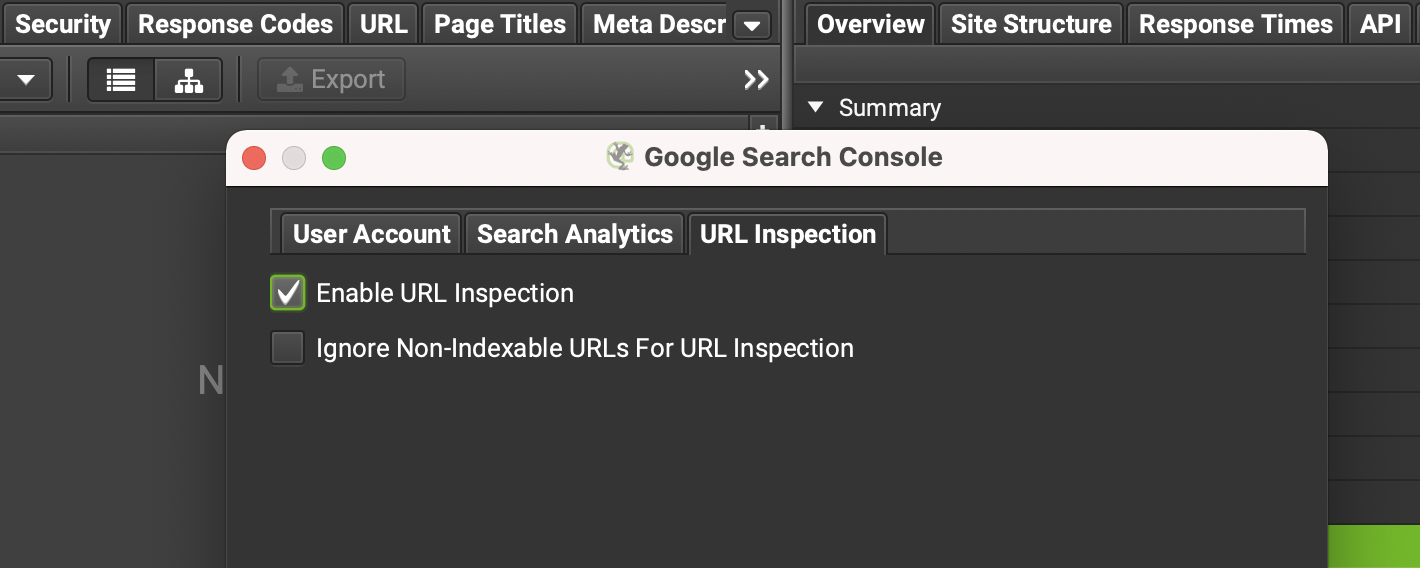
Asegúrate de marcar la casilla de Habilitar Inspección de URL, que encontrarás en la pestaña URL Inspection. También puedes marcar, si quieres, la opción de ignorar URLs canonicalizadas, que dan error, redirigen o que llevan un noindex, para de esa forma no gastar tus solicitudes diarias en URLs que no tenías intención de indexar.
Al acabar el rastreo, tendrás un informe extra con todos los datos extraídos por Screaming Frog de la API de inspección de URLs, y que incluyen una serie de filtros útiles para identificar o monitorizar problemas, como “URL indexable no indexada por Google” o “Canonical declarada por el usuario no seleccionada por Google”.
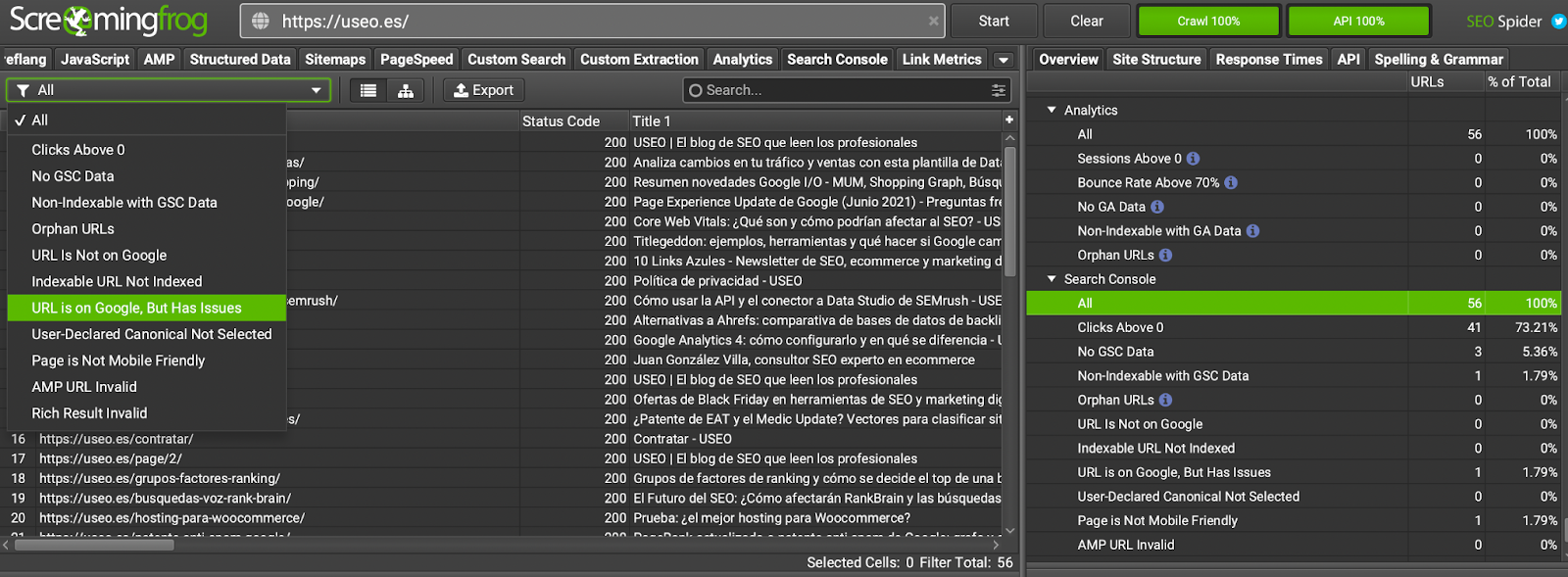
Estos filtros / informes te dirán:
- Qué URLs no se encuentran indexadas
- Qué URLs no se encuentran indexadas, a pesar de tener una meta robots que permite la indexación
- En qué URLs Google ha escogido una canonical diferente a la que tú has indicado
- Qué URLs no pasan el test de usabilidad móvil
- Qué URLs AMP no son válidas
- Qué URLs tienen algún resultado enriquecido no válido (incluyendo tanto errores como avisos)
Como siempre en Screaming Frog, podrás cruzar estos datos con otros extraídos del rastreo, o del resto de APIs integradas en la rana, y descargarlos para usarlos donde quieras (ver última sección del post para algunas ideas).
Sitebulb
Lo de Sitebulb no ha tenido menos mérito que Screaming Frog, ya que esta excelente herramienta de auditoría SEO también se actualizó unas pocas horas después, ofreciendo no sólo estos mismos datos, sino una serie de informes con gráficas muy visuales para comprender de un vistazo el estado actual de indexación de tu sitio.



Como se puede ver en los pantallazos, los filtros son similares a los de Screaming Frog, y además podemos por ejemplo ver nuestras URLs por el número de días que ha pasado desde el último rastreo por parte de Google.
Si habilitas la conexión, Sitebulb solicita a la API información de las 2000 URLs de mayor URL Rank que encuentre en el rastreo (URL Rank es su métrica de autoridad interna, similar a PageRank).
Plantilla Bulk Page Checker para Google Sheets
Si no tienes licencia de Screaming Frog o de Sitebulb, pero quieres integrar datos de la API dentro de Sheets, puedes usar también la plantilla Bulk Page Checker de Mike Richardson, que tuvo el mérito de ser el primero (que yo sepa) en desarrollar una integración para la nueva API.
El único problema es que necesitas hacer tú todo el proceso de activación y autorización de un servicio dentro de la cuenta de Google Cloud Platform, prácticamente como si te conectases a la API por Python u otro tipo de script (realmente lo que estás haciendo es conectarte directamente con Apps Script).
Aparte, Google Sheets no suele lidiar bien con cientos o miles de llamadas a una API dentro de la misma hoja, y probablemente experimentarás algo de lentitud, time outs, etc. Yo recomiendo conseguir los datos por otra herramienta o método, y luego traerlos a Sheets para manipularlos.
Con tu propio script (Python, nodejs, etc)
Si te manejas bien programando o eres partidario de crear tus propias herramientas para casos de uso específicos, o simplemente, porque te gusta más, hay ya varios tutoriales que te pueden ayudar.
Simplificando, el proceso siempre va a ser el mismo:
- Crear un proyecto o aprovechar uno existente en Google Cloud Platfom
- Crear un service account con sus credenciales
- Crear las API keys necesarias para autorizar a este servicio el acceso a los datos
- Añadir a la cuenta de servicio como Owner en la propiedad de Search Console que vas a inspeccionar
- Hacer la llamada a la API
No voy a repetir lo que han escrito otros, sino que te dejo por aquí los enlaces a estos tutoriales:
- Cómo usar la URL Inspection API con Python, de Álex Romero López (tutorial en español)
- Google URL Inspection API with Python, de JC Chouinard (tutorial en inglés)
- How to use the newest URL Inspection endpoint from the Google Search Console API with Node.js, de José Luis Hernando (tutorial en inglés)
Qué se puede hacer con estos datos
Una vez que Google nos ha dado acceso a estos datos vía API, aunque sea con límites (lógicos, ya que es una API gratuita), las posibilidades son casi infinitas, y estoy seguro de que en las próximas semanas y meses vamos a ver un montón de aplicaciones diferentes para esto datos.
Por lo pronto, se me ocurren tres aplicaciones muy sencillas:
Automatizar la inspección de las últimas URLs publicadas de un sitio
He dicho desde el principio que una de las grandes ventajas de tener una API es que ya no dependemos de una acción manual para consulta el estado de indexación de nuestras URLs. Vamos a verlo en la práctica.
Imaginemos que tenemos un sitio que añade páginas nuevas con mucha frecuencia, ya sea un ecommerce añadiendo nuevos productos, o un blog con nuevos posts cada día.
Tanto con Screaming Frog como con Sitebulb podemos programar un rastreo diario, que incorpore conexión a la API de Search Console, para extraer todos los datos de estado de indexación.
Para ahorrar recursos, especialmente si el sitio tiene más de 2000 URLs, y como no es probable que de un día para otro se hayan añadido más de 2000 URLs, podemos limitar el rastreo (a 2000 URLs, o a lo que sea aplicable) e incluso podemos partir de un punto que no sea la home, sino la página desde donde se enlace al nuevo contenido.
Por ejemplo, en un ecommerce esto podría ser la página de Novedades, si existe, o en un sitio con blog podría ser la home del blog. En WordPress, el sitemap por lo normal va a mostrar primero las últimas páginas actualizadas, por lo que también podría ser un buen punto de partida para el rastreo.
Lógicamente, podemos desmarcar también el rastreo de archivos de recursos, como imágenes, JS, CSS, etc.
Ahora, lo interesante es automatizar también la descarga de los informes relevantes para estar al día de problemas. Como hemos dicho, Screaming Frog tiene filtros concretos para incidencias tipo URLs indexables que no han sido indexadas por Google, o URLs en los que la canonical elegida no es la URL declarada en el código de la página. Si esto es lo que nos interesa saber, podemos automatizar la exportación de estos informes a un folder de Drive, e incluso con un conector tipo Integromat podemos enviar un email a la persona adecuada, adjuntando estos informes.
Para más ideas sobre cómo integrar estos datos dentro de un flujo de automatización de SEO, puedes echarle un vistazo a la presentación de Iñaki Huerta «Que lo haga otro: automatizaciones SEO para vivir mejor.»
Rastreo de un sitio y consulta a la API «por partes»
Como dije al hablar de los límites de la API, estamos constreñidos a consultar 2000 URLs al día. Si nuestro sitio es más grande, esto quiere decir que tendremos que consultra diferentes partes del sitio en distintos días, pero eso no quiere decir que no se pueda (y además puede automatizarse).
Imaginemos que tenemos una tienda seis grandes categorías de producto, que están presentes como carpetas en la URL tanto de las categorías como de sus productos, y un blog, cuyos posts también están anidados dentro de una carpeta /blog.
Suponiendo que cada una de estas 7 partes del sitio no pase de las 2000 URLs, podemos programar cinco rastreos semanales para abarcarlo todo. Por ejemplo podríamos organizarlo así:
- Todos los lunes: categoria-1
- Todos los martes: categoria-2
- Todos los miércoles: categoría-3
- Todos los jueves: categoría-4
- Todos los viernes: categoría-5
- Todos los sábados: categoría-6
- Todos los domingos: blog
Para rastrear las URLs de una carpeta y dejar fuera del rastreo las de las otras carpetas, basta con usar la opción Include URLs al configurar el rastreo (esto vale también para Sitebulb y la mayoría de crawlers).
De esta forma, los datos de rastreo y de la API de inspección de cada URL del sitio siempre tendrían, como mucho, un retraso de 6 días.
Crear unos “mini-logs” de rastreo de Google
Esta idea la he tomado de este tuit de Mike Richardson, y es realmente buena.
Si nuestro sitio no es demasiado grande, 2000 URLs, especialmente si son las URLs más importantes del sitio, pueden ser suficientes para hacernos una idea de con qué frecuencia rastrea Google las distintas partes del sitio.
En lugar de analizar esto URL por URL, que sería difícil de asimilar al tener datos de 2000 páginas, podemos dividir los datos por carpeta o subfolder, y asignar una media de días desde el último rastreo a cada carpeta del sitio. Ahora ya podemos verlo todo con más claridad.
Esto se puede hacer muy fácilmente en Data Studio, o con una tabla dinámica en Google Sheets. Lo único que debemos hacer es extraer el primer subfolder de cada URL, con una fórmula como esta (para Google Sheets):
=iferror(REGEXEXTRACT(A2, "http[s]:\/\/.*?\/(.*?)\/"))
A continuación, inserta una tabla dinámica, y para mayor claridad, usa un filtro para dejar fuera todas las URLs que no tengan fecha de último rastreo por Google. Después, usa como fila el nuevo campo que has creado para la carpeta, y como valor pon los Días desde el último rastreo. Ordena por esta métrica en valores ascendentes, et voilá, tendrás un listado de las carpetas del sitio, ordenadas por tiempo media desde la última visita de Google.

Por supuesto, esto no pretende ser un sustituto para un análisis de logs en condiciones, pero sirve para hacerse una primera idea estimada, y además, te dará información más completa cuantos más rastreos vayas combinando.
Si tienes datos de la URL Inspection API de los últimos 15 días, y aún así hay una parte de tu sitio que Google lleva sin solicitar por ejemplo más de 20 días, mientras que otras las ha rastreado ya 6 o 7 veces, hay ahí un problema
(Pequeño aviso, si tú mismo solicitas rastreo manual desde Search Console para alguna URL, estarás “contaminando” levemente estos datos, ya que el dato que aparecerá para esa URL cuando luego consultes la API será precisamente el de la fecha en la que Google rastreó a petición tuya).
Y hasta aquí ha llegado el post. ¿Se te ocurren más aplicaciones interesantes para extraer datos jugosos que antes no podíamos tener, dentro de los límites actuales de la API?

Gran artículo SEO. No lo pones fácil para retwitear sin botones sociales. Pero ya está el pájaro en el aire.
Jaja, sí, es que tengo una «cruzada» personal contra los botones sociales, siempre me ha parecido que en la mayoría de sitios estorban más que ayudan, pero bueno, le daré una nueva ojeada y si encuentro unos que no ralenticen la web ni queden como un pegote los añadiré sin duda.
Muchas gracias, Mel! 🙂
https://es.wordpress.org/plugins/scriptless-social-sharing/
Genial, lo pruebo!
Muchas gracias, Juan por siempre compartir información actualizada y útil. Saludos!
Como en otras ocasiones muchas gracias Juan por el artículo y el aporte. Nosotros ya estamos comenzando a usarlo con Google Sheets para los sitios más pequeños. Parece que Netpeak Spider también conectará en breve con la API (herramienta muy parecida a Screaming Frog).
Gracias! Sí, cada vez hay más herramientas que están ofreciendo integración. Voy a hacer una actualización en breve para listar al menos todas las que conozca que tengan esa integración.
Gracias máster Juan González por compartirnos esta información valiosa, como siempre dando puro oro a la comunidad seo.
Como dices, 2000 requests al día se hace poco para sitios grandes, pero creo que para sitios pequeños y nichos nos viene super bien… Así que bueno ya no tendremos que esperar la conduerma de Google para la indexación
Vaya! desconocía esa información, que bueno es aprender, gracias por compartir 😀
Gracias por tanta información! Anduve buscando información sobre Screaming Frog y encontré tu sitio, fue de lo mejor que me pasó en el día! Sigue así!
Muchas gracias, Ernesto!