

En este post te voy a hablar de una patente de Google que introduce una importante modificación sobre el PageRank, el algoritmo para rankear la web con el que Google se convirtió en el buscador más importante el mundo.
La patente se titula “Producing a ranking for pages using distances in a web-link graph” (“Generando un ranking de páginas usando distancias en un grafo de enlaces”).
Fue presentada en 2006 y concedida por primera vez en 2015, y luego en abril de 2018, tras presentar Google una nueva patente con leves cambios sobre la original.
Las dos versiones podéis leerlas aquí y aquí. Para no liarnos, en el post hablaré siempre de la patente 9165040, que es el número del documento original.
¿Por qué es importante? En primer lugar, porque presenta una versión “mejorada” y menos manipulable de PageRank.
Para seguir, algunos (entre los que me cuento) ven en esta patente el mecanismo detrás de Penguin, o al menos de su última versión, la que según Google es capaz de devaluar la importancia de los enlaces tóxicos o incluso ignorarlos, en lugar de penalizar al sitio que recibe esos enlaces.
Además, no falta quien cree que esta patente podría estar relacionada con la actualización de agosto de Google.
¿Te parecen razones suficientes para destripar la patente? Pues vamos a ello:
El “problema” del PageRank
¿Qué problema intenta resolver esta patente para Google? Ni más ni menos, el hecho de que PageRank es vulnerable a la manipulación con enlaces, algo que se sabe desde los albores del SEO.
Para que veas que no me lo invento, así describe la patente esta debilidad de PageRank en su introducción:
“…the simple formulation for computing the PageRank is vulnerable to manipulations. Some web pages (called “spam pages”) can be designed to use various techniques to obtain artificially inflated PageRanks, for example, by forming “link farms” or creating “loops.” “
Traduzco: La sencilla fórmula (previamente descrita) para computar el PageRank es vulnerable a manipulaciones. Algunas páginas web (denominadas páginas spam) pueden usar una serie de técnicas para obtener PageRanks inflados artificialmente, ya sea formando “granjas de enlaces” o “bucles” de enlaces.
Una primera alternativa: el TrustRank
¿Cómo superar este hándicap de PageRank? La respuesta más obvia es creando un grupo de páginas “semilla”, cuya autoridad y confianza está fuera de duda, y a partir de ahí seguir los enlaces salientes, traspasando autoridad sólo de las semillas a las páginas enlazadas, y de estas al siguiente nivel de páginas enlazadas, y así sucesivamente.
Pero, tal y como explica la patente en su introducción, este método (conocido como TrustRank) tiene otro fallo: hay que calcular un PageRank para todo el sistema en relación a cada una de las semillas. Es decir, pasas a tener tantos PageRanks diferentes como semillas tiene tu sistema.
Para que el TrustRank sea realmente efectivo, necesita tener muchas semillas diferentes. Así, según crece el número de semillas, la complejidad de calcular todo el sistema se multiplica.
Tiene que haber un sistema mejor para eliminar el efecto de la manipulación de enlaces por parte de los spammers. Eso es lo que explica el núcleo de la patente 9165040.
Usar páginas semilla y distancias de enlaces para eliminar el spam de la ecuación
Para superar la debilidad ante el spam de PageRank, sin caer en la complejidad de TrustRank, esta patente propone asignar puntuaciones (o distancias) a cada enlace, en lugar de calcular la distancia (en términos de clics o enlaces) que separa a cada página de una semilla.
Si parece un poco complicado de entender, no te preocupes, que lo voy a explicar paso a paso.
Partimos de un universo de páginas, entre las cuales existen una serie de enlaces. En la práctica, esto es el total de páginas de la web que Google conoce, aunque para el ejemplo vamos a pensar algo más pequeño, por ejemplo, un set de 10 páginas. Este conjunto de páginas (nodos) y los enlaces que existen entre ellas (aristas) es lo que se llama un grafo de enlaces, o link-graph.
Además, tenemos un set más reducido de páginas semilla, que lógicamente están conectadas con ciertas páginas del set grande. Pongamos que tenemos 3 semillas.
Ahora le vamos a dar una puntuación a cada enlace del universo analizado, en función de una serie de propiedades de los enlaces, y de propiedades de las páginas enlazadas entre sí. La patente llama “distancia” a esta puntuación asignada al enlace, y en general es una distancia mayor cuanto menor es la calidad del enlace (distancia inversamente proporcional a la calidad).
Por ejemplo (un ejemplo mío, no de la patente), si la temática de la página que enlaza es totalmente distinta a la de la página que recibe el link, esto podría ser considerado un enlace con una distancia mayor que la de un enlace entre dos páginas muy similares en su temática.
Pero puede haber más criterios para definir la distancia de los enlaces. La patente cita varias formas posibles de establecer esta puntuación para cada enlace, sin precisar cuál de ellas propone usar, o si propone una combinación de métodos (esto último es lo más probable):
- Uno de los factores que puede decidir la distancia de los enlaces es el número de enlaces salientes de la página que enlaza, resultando una mayor distancia cuanto mayor es el número de enlaces salientes (esto sería bastante similar al PageRank, que traspasa menos PR cuanto mayor es el número de enlaces salientes).
- Otros factores citados en la patente serían la posición del link en la página y la font usada en el anchor. La patente deja claro que podría haber muchos otros factores, pero no especifica cuáles. Por especular, quizá la afinidad temática entre página fuente y destino del enlace podría ser un factor (esto es cosecha mía, no aparece en la patente)
Ahora que ya tenemos la distancia de cada enlace entre las páginas del set, viene la parte más importante: rankearlas. El método general propuesto es calcular la distancia más corta entre cualquier página y una semilla, y a partir de ahí ordenar todas las páginas del set en base a este criterio.
Usando la aplicación más sencilla posible de este método, para cada una de las 10 páginas del set de nuestro ejemplo, tomaríamos la distancia más corta a cualquiera de las 3 semillas, y las ordenaríamos así: la página con la distancia más corta en primer lugar, la página con la siguiente distancia en segundo lugar, etc.
Lo malo es que no todo es tan sencillo, y aquí la patente introduce varias formas de “complicar” esta forma de rankear páginas. No voy a repetir todos y cada uno de los métodos propuestos (para eso lo mejor es leer directamente la patente), pero sí quiero destacar varios hechos importantes:
- Puede considerarse la distancia más corta de una página a cualquier semilla, o las distancias más cortas a un número por determinar de semillas (a este número la patente lo llama k). Incluso, puede que una vez determinado k (imaginemos k=6), la semilla desde la cual se calculan las distancias es la sexta semilla más cercana a la página (porque k=6 en este ejemplo).Esto me parece muy importante, porque si el ranking de una página depende de la distancia más corta no desde una semilla cualquiera, sino de la distancia más corta desde seis, siete o veinte semillas distintas, la posibilidad de manipular a base de enlaces artificiales se hace realmente difícil, por no decir que es casi imposible.
- Cuando hay un número relativamente alto de semillas, se le puede asignar “pesos” a las semillas, para permitir que la proximidad a algunas semillas tengan mayor incidencia en el ranking que otras.
- Cada semilla puede ser una sola página, o una serie de páginas dentro de un sitio.
- La efectividad de las semillas puede medirse cada cierto tiempo, de acuerdo a los rankings que produzcan. Si los rankings obtenidos no se consideran precisos, se puede variar el peso de cada semilla, buscando un nuevo criterio para ordenar las páginas que produzca resultados de más calidad.
¿Qué requisitos deben cumplir las páginas semilla? Como he dicho antes, ser una fuente incuestionable de autoridad y confianza, y contener un número razonable de enlaces salientes. Ejemplos concretos citados por la patente son el Google Directory (desaparecido en 2011) y el New York Times.
Resumiendo lo que hemos visto hasta ahora, y prescindiendo de detalles y variaciones del método fundamental, lo que esta patente propone es:
- Definir una serie de páginas semilla, que son la “fuente” de las que fluye la autoridad
- Calcular una distancia para cada enlace entre las páginas del grafo
- Calcular la distancia más corta entre cada página del grafo y una semilla (o un número x de semillas), sumando la distancia de cada uno de los enlaces que forma parte de la cadena de links que conecta a la semilla con la página (ya sea esta cadena de uno, dos o mil enlaces)
- Rankear todas las páginas del grafo de acuerdo a la distancia más corta que se pueda trazar entre la página y una semilla o serie de semillas (cuanto más corta la distancia, mejor rankeada la página)
Aquí, explicado en más pasos y por medio de un diagrama de flujo incluido en la patente:

Un grafo de enlaces “reducido” (Reduced Link-Graph)
Con lo que hemos visto, ¿cómo evita esta patente la contaminación creada por los enlaces spam?
Muy sencillo: no los tiene en cuenta, ya que sólo está usando para rankear las conexiones de menor distancia (o mayor calidad) entre las páginas del grafo.
Todos los “caminos” que crean una conexión de mayor distancia entre una página cualquiera y las semillas pueden son ignoradas por este algoritmo, ya que no las necesita para calcular el ranking.
Son “ruido”, enlaces redundantes, datos y complejidad innecesaria para calcular un ranking que se puede calcular de una manera más sencilla.
Por eso la patente habla de un grafo de enlaces “reducido”, la parte del grafo que le basta al algoritmo para calcular un PageRank que se basa sólo en las mínimas distancias de las semillas a las páginas del grafo. Este algoritmo es más efectivo por tanto que el PageRank “normal”, que contiene todos los nodos y aristas del grafo, y que incluye por tanto ruido y enlaces manipulados.
Queda una cuestión importante: ¿y si tengo una página que no está conectada de ninguna manera a ninguna semilla, ni siquiera por una cadena de 1000 enlaces consecutivos?
Entonces, el PageRank de esa página es cero, o casi cero (si se aplica el damping factor, que es la probabilidad ínfima de que un usuario se aburra de seguir enlaces y ponga la url de esa página en la barra del navegador).
Entonces, si creas enlaces artificiales hacia una página desde páginas spam, creadas por ti o por otros, y que lógicamente no tienen ninguna conexión con semillas, esos enlaces no contarán para nada y el PageRank de tu página seguirá siendo el mismo.
Es decir, a efectos del PageRank no habrá habido ninguna manipulación. Objetivo de Google conseguido.
Te lo voy a mostrar todo a continuación con un ejemplo, sacado directamente de la patente.
Ejemplo de grafo de enlaces reducido
Recuerda que teníamos un grafo de 10 páginas y 3 semillas, tal y como aparece en esta imagen incluida en la patente 9165040B1.
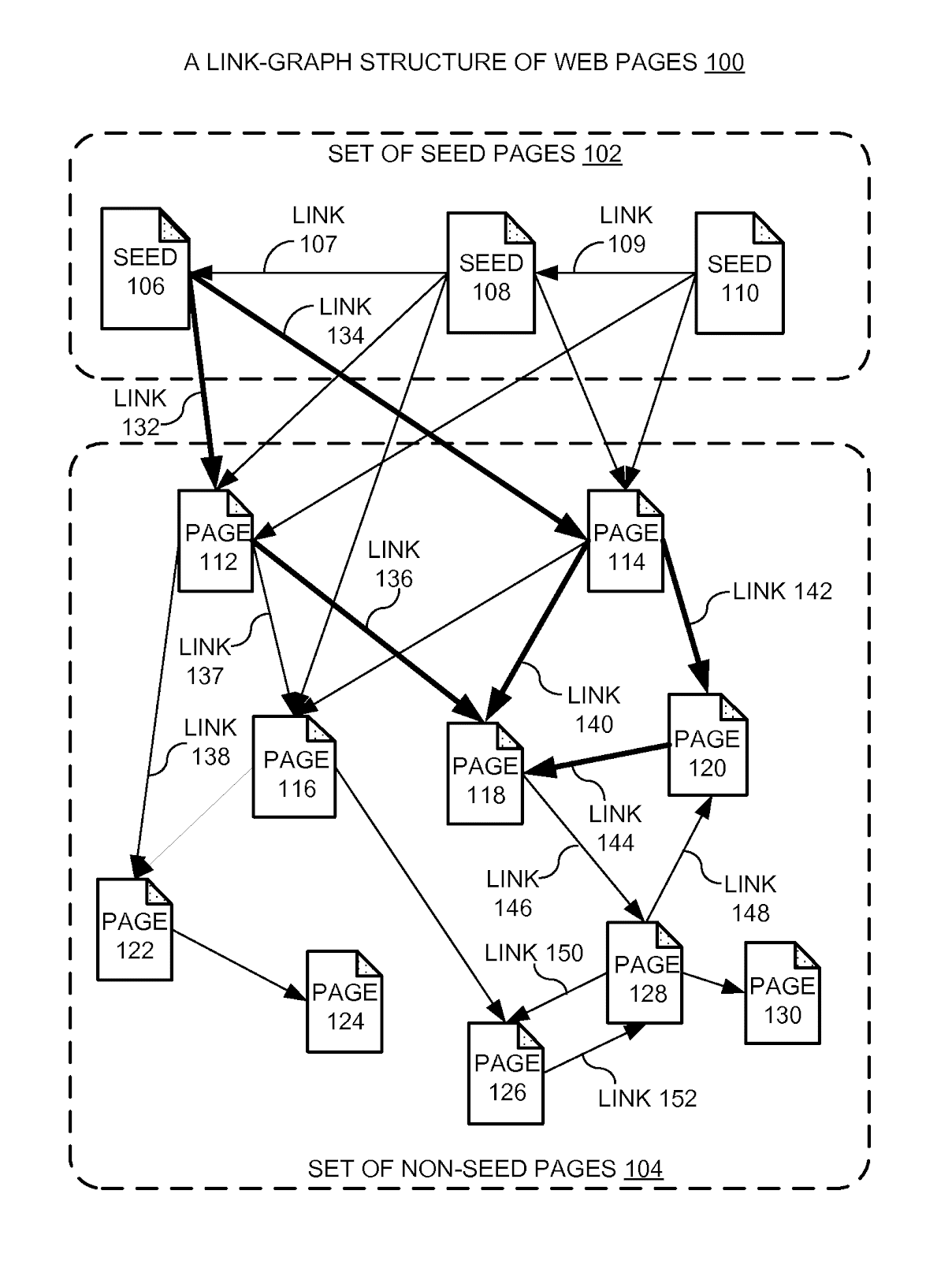
Ahora imaginemos que vamos a determinar el PageRank de cada página, en base a la distancia más corta a la semilla 106.
La página 118 del gráfico no está conectada directamente con la semilla 106, pero sí está conectada a través de enlaces que llegan desde otras páginas, conectadas a su vez a la 106. En concreto, hay 3 posibles formas de llegar desde 106 a 118:
- Pasando por la página 112
- Pasando por la página 114
- Pasando por las páginas 114 y 120
No he sacado la regla, pero me parece claro que, dadas las distancias asignadas en la imagen a cada enlace, el camino más corto es el que pasa por la página 112.
Eso querría decir que los enlaces que van desde la 114 y desde la 120 hacia la 118 no forman parte de la distancia más corta entre 106 y 118, y por tanto no son necesarios para calcular el PageRank de la 118.
Aplicación de esta patente: relación con Penguin y con el update de agosto
Vale, la teoría está muy bien, pero ¿se aplica esta patente en el mundo real?
Como ocurre con todas las patentes de Google, lo único de lo que tenemos certeza es de que sus ingenieros han estado trabajando en el problema descrito por la patente, y que esta idea les ha parecido lo suficientemente buena como para protegerla con una patente, y para introducir unos pequeños cambios tras octubre de 2015 (si es algo en lo que trabajaron en 2006 pero luego perdieron interés, difícilmente habrían presentado una continuación de la patente en 2015).
Por supuesto, eso no es garantía de que este método esté en funcionamiento en Google o lo haya estado en algún momento.
Pero no se puede negar que el sistema descrito tiene bastante parecido con uno de los updates o algoritmos que todo SEO conoce: Penguin.
Recordemos algunas declaraciones hechas desde Google en torno al lanzamiento de la última versión de Penguin en septiembre de 2016 (Penguin 4.0 o Penguin en tiempo real):
- Penguin es granular, no afecta a dominios enteros, y además ahora devalúa el spam, ajustando el ranking de una página basándose en ciertas señales de spam (Gary Illyes en el anuncio oficial)
- Penguin 4.0 es incluso capaz de identificar el spam e ignorarlo de cara al ranking de una página (respuesta de Gary Illyes a una pregunta de Barry Schwartz tras el anuncio oficial)
La duda sería: si este método se patentó en 2006, ¿cómo es que Penguin no llegó hasta abril de 2012?
Una explicación probable sería que en 2006 idearon el sistema, pero eso no quiere decir que estuviese listo para funcionar en el mundo real. Los casi seis años que van hasta el lanzamiento de Penguin podrían ser un tiempo de pruebas o incluso de superar obstáculos técnicos para poder aplicar la idea.
Llevando esto más allá, es posible que los primeros Penguin fueran versiones “imperfectas” de este método, pero necesarias para ir ganado la batalla al spam, aunque fuera a cañonazos y hundiendo a veces un pequeño porcentaje de sitios que no lo merecían.
¿Por qué en septiembre de 2016 Google estaba en condiciones de declarar que Penguin era ya parte del núcleo de su algoritmo, y que no habría más updates manuales de Penguin? ¿Quizá porque ya funcionaba como siempre había pretendido esta patente?
Entiendo que queda en el aire un elemento de especulación, y que conocer la patente en ningún modo garantiza conocer el modo en el que opera Google, ni el valor real que le asigna a cada enlace. Pero sin duda ayuda.
¿Hubo un factor de enlaces en el update de agosto?
¿Y qué hay del último update “gordo”, el de agosto de 2018 (y mal llamado Medic Update)?
Recordemos que las semillas se pueden cambiar para mejorar la efectividad del algoritmo, o se pueden añadir nuevas. Quizá en 2006 cuando se presentó la patente original se estimaba que calcular las distancias a 4 o 5 semillas era suficiente (o el máximo número manejable) y puede que ahora se haya aumentado el número, creando una mayor complejidad en el cálculo, pero un link-graph más reducido y unos rankings más exigentes.
Tampoco sería extraño que, para lograr un mayor grado de fiabilidad en webs relacionadas con temas sensibles tipo salud o finanzas, se hayan añadido semillas de estas temáticas, o se les haya dado un peso relativamente mayor.
Dicho esto, que conste en acta que no pienso que el update de agosto sea únicamente una cuestión de enlaces, y tampoco que fuera algo dirigido exclusivamente a reordenar las serps en el nicho de salud o en los llamados nichos YMYL (Your Money Your Life).
Pienso que lo que afirma Google es cierto: que es un update al núcleo de su algoritmo. Y eso sin duda incluye otras cuestiones: relevancia (cambios a cómo calculan la Information Retrieval Score), diferencias en cómo se evalúa la intención de búsqueda…
He visto suficientes ejemplos de bajadas o subidas en webs donde los enlaces no parecen ser un factor, o desde luego no el único (sitios con problemas técnicos, contenido duplicado, canibalizaciones, keyword stuffing, etc).
Ahora, si se quiere un indicio de que el factor enlaces sí ha podido tener cierto peso en agosto, valga el post de Sistrix donde se muestra cómo una gran cantidad de sitios que habían tenido problemas con Penguin en el pasado, los volvieron a tener con el Medic Update. Sí, es una mera correlación, y también se puede establecer una correlación similar entre Panda y la actualización de agosto, pero ahí está para el que lo quiera analizar.
¿Ha dejado de usar Google el PageRank de siempre?
Y no, no hablo del PR mostrado por la Google Toolbar y que dejó de actualizar en 2013. 😉
Hablo de este PageRank. Google afirma que, 20 años después, sigue usando su algoritmo PageRank para rankear documentos para una búsqueda. Pero esto podría interpretarse de muchas formas.
¿Quizá lo sigue usando, pero lo que ha cambiado es la forma de calcularlo, y ahora sólo lo calcula de acuerdo a las distancias en un link-graph reducido?
¿O lo sigue usando, pero ahora tiene un peso menor? En cuyo caso, podría haber una puntuación por PageRank “tradicional”, y otra por PageRank según el método del grafo reducido.
Concretamente, Matt Cutts decía en este vídeo que el PageRank era uno de los métodos que tienen para calcular la autoridad, pero que también usan otros.
Sigo en lo mismo: no tenemos certeza, pero me parece muy poco probable que Google haya patentado dos veces este método y que no le dé ningún uso.
¿Hay herramientas o métodos para estimar distancias entre enlaces?
Sé lo que te estás preguntando. Si Google mide así el peso de los enlaces, y si un montón de los enlaces que hay en la red tienen un peso de 0 de acuerdo a este algoritmo, ¿hay alguna herramienta o algún método que te pueda decir qué enlaces son buenos y cuáles no cuentan para nada?
Bien, de la misma manera que el PageRank se puede manipular, se puede estimar. La mayoría de herramientas que hacen análisis de links (Moz, Ahrefs) tienen su propia estimación del PageRank, basada en el número de páginas y enlaces que conocen (siempre menor que Google).
La excepción más clara es Majestic, que tiene una métrica llamada TrustFlow y que se basa en medir la autoridad que fluye desde una serie de páginas semilla.

Fuente: Majestic
El TrustFlow de Majestic es bastante similar al TrustRank, que comentaba al inicio del post, y por tanto no se puede pretender una coincidencia perfecta con el reduced link-graph de Google. Pero es un comienzo. Creo que cualquier consultor o agencia que se tome en serio el link building debería tener un ojo puesto en esta métrica.
Existen otros métodos más o menos escalables para hacer aproximaciones al grafo que realmente usa Google, pero me las voy a guardar para otro post.
Por ahora, espero tus comentarios: ¿crees que realmente Google ignora el spam? Y si es así, ¿crees que los SEOs tenemos alguna forma de identificar las semillas que usa Google, o de manipular este sistema?
¿Te ha parecido útil este post? Compártelo en Twitter para que ayude a mucha más gente.

Suena a paso firme para evitar la manipulación de enlaces, pero no definitivo, al menos de momento. Tocará afinar todavía más 🙂
Lo que se aprende en este blog oye.
Interesante tema, lo que veo es que ahora más que nunca toca tener mucho cuidado con la calidad de enlaces que apuntan a nuestros sitio y que si o si debería ser relacionado a nuestra temática, aunque para algunas temáticas será más complicado, creo que aun seguirán teniendo relevancia los enlaces de otras temáticas siempre y cuando el visitante que llegue interactue en nuestro sitio y se quede más tiempo.
Gracias por la información!
Muy interesante tema. Si bien no hay nada definido o confirmado, en realidad en el SEO tampoco hay ‘verdadades absolutas’ por lo tanto es muy aceptable.
Me gustó la parte de ‘reduced link-graph’ y el ruido que representan los enlaces de baja/nula calidad. Si bien la calidad reina hace tiempo, incluso si alguien puede posicionar sin calidad, hay que pensar a futuro y en un futuro cercano, ya no podrán más.
Sobre la actualización del 01/08 no tengo comentarios; he visto casos de todo tipo, y donde un tema parece quedar ‘resuelto’, luego aparecen contraejemplos a refutarlo.
En fin, de nuevo gracias por tan buen y detallado artículo Juan.
Artículo muy interesante aunque no hay nada claro lo único cierto es que lo que más influye en el SEO de tu web es buen contenido y enlaces de calidad desde webs relacionadas con tu actividad.
Si este blog no es semilla, no lo entiendo!!!
Grande! Jaja, gracias!
Que buen post, super interesante. Lo que no entendi es… ¿Que tanto cuodado hay que tener con enlaces sin autoridad? Porque es que de ser asi importan poco, no afectan positivamente pero tampoco como algo negativo, por lo menos eso, segun entendi, no es algo tan malo a fin de cuentas.
Claro que rankear a punta de enlaces se hace cuesta arriba eso si…
Hola, Daniel. Efectivamente, si tomamos al pie de la letra la patente, estos enlaces que no están en contacto de ninguna manera con las semillas son irrelevantes, no aportan nada positivo, pero tampoco negativo.
No por el hecho de crear un enlace desde una página de valor cero hacia otra, se sigue necesariamente que ese enlace sea spam. Pero sí se cumple casi siempre que los enlaces creados con el objeto de manipular el algoritmo de Google no tienen ningún contacto con las páginas semilla. Por eso a Google le interesa ignorar este tipo de enlaces, y ya se está quitando buena parte del spam de enlaces.
Me acabo de desayunar este post de principio a fin. Oro en paño, muchas gracias Juan. Pero si se aplicara el reduced link graph, las varias páginas que venden paquetes de linkbuilding etc ¿no estarían un poco con el culo al aire? Dudo que los links que generan la mayoría de ellas estén en la distancia más corta entre semilla y página de destino… ¿Qué opinas? ¡Gracias!
Gracias, Davide! Pues el objetivo de Google con esta patente es claramente reducir el efecto del spam y la manipulación de enlaces en el link graph, y por tanto en su algortimo de rankeo. Por lo tanto, sí, las páginas que venden enlaces serían claras perjudicadas de la aplicación de este sistema. Al fin y al cabo lo que hacen es más o menos ofrecer un «supermercado» de la manipulación de enlaces (siempre que estos enlaces no se marquen con «nofollow» o con el nuevo atributo «sponsored». 😉